🚀 AiPy大模型适配度测评第二期报告
📋 背景说明
为了让AiPy用户获得更卓越的AI体验,我们持续关注并评测市场上最新的大语言模型。在首期测评获得用户广泛认可后,AiPy大模型适配度测评第二期如约而至!
本期测评特别纳入了近期发布的重磅模型——包括备受瞩目的Kimi-K2、Google最新的Gemini-2.5 Pro、马斯克团队的Grok-4,以及Anthropic的Claude-4系列。这些新锐模型与首期表现优异的DeepSeek-V3、豆包等模型同台竞技,通过多维度、全方位的测试,为用户呈现最客观、最实用的性能对比分析。
相较于首期测评,我们显著丰富了评估维度,将任务执行轮数和Token消耗成本纳入综合计分体系,力求为用户提供更加全面、客观的模型性能参考,助力AiPy平台选择最适配、最高效的LLM模型。
📊 测试概况
本次测评采用标准化测试框架,通过多元化任务场景全面检验各模型的实际应用能力。测试涵盖系统分析、可视化分析、数据处理、交互操作和信息获取等五大核心应用场景,确保评估结果的客观性和实用性。
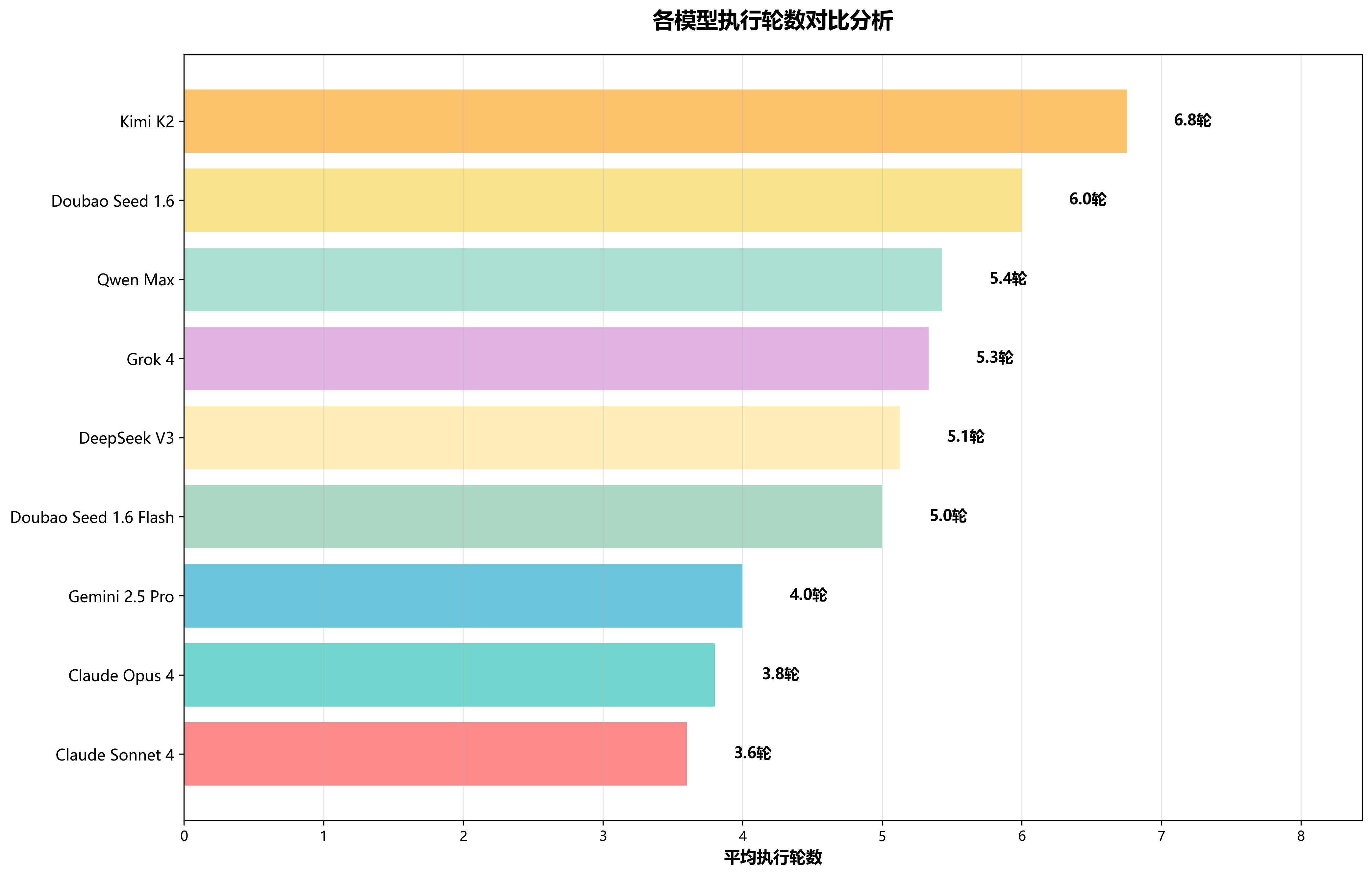
🏆 综合排名
基于成功率(80%)、Tokens消耗(10%)、时间效率(5%)和执行轮数(5%)四个维度的综合评分,Claude Opus 4以卓越的92.1分夺得桂冠,展现了Anthropic在大模型领域的技术实力。紧随其后的Claude Sonnet 4和Doubao Seed 1.6分别以91.3分和84.6分占据亚军和季军位置。
| 排名 | 模型名称 | 综合得分 | 成功率 | 平均时间 | 平均轮数 | 平均Tokens |
|---|---|---|---|---|---|---|
| 1 | Claude Opus 4 | 92.1 | 100.0% | 166秒 | 3.8轮 | 39070 |
| 2 | Claude Sonnet 4 | 91.3 | 100.0% | 183秒 | 3.6轮 | 47232 |
| 3 | Doubao Seed 1.6 | 84.6 | 100.0% | 598秒 | 6.0轮 | 61981 |
| 4 | Grok 4 | 80.2 | 90.0% | 323秒 | 5.3轮 | 54081 |
| 5 | Gemini 2.5 Pro | 77.0 | 80.0% | 119秒 | 4.0轮 | 32134 |
| 6 | DeepSeek V3 | 74.8 | 80.0% | 218秒 | 5.1轮 | 37145 |
| 7 | Kimi K2 | 69.4 | 80.0% | 525秒 | 6.8轮 | 54803 |
| 8 | Qwen Max | 60.5 | 70.0% | 171秒 | 5.4轮 | 104945 |
| 9 | Doubao Seed 1.6 Flash | 43.7 | 40.0% | 73秒 | 5.0轮 | 41422 |
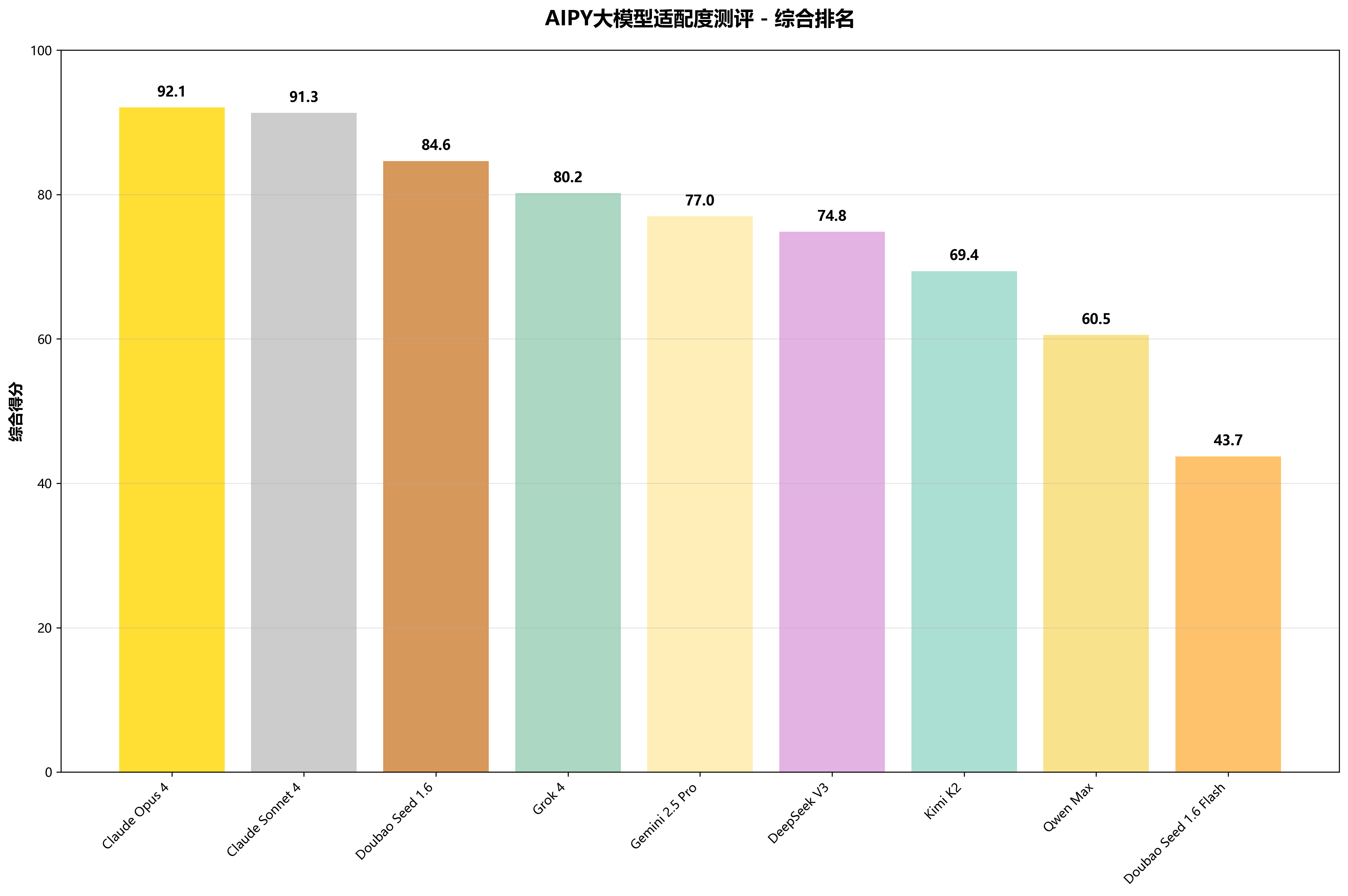
📈 各模型成功率对比分析
成功率是衡量模型实际应用价值的核心指标。从测试结果看,头部模型在任务完成能力上表现出显著优势,Claude系列模型均保持了100%的完美成功率,体现了其稳定可靠的性能表现。Doubao系列和其它主流模型也展现了良好的任务执行能力。
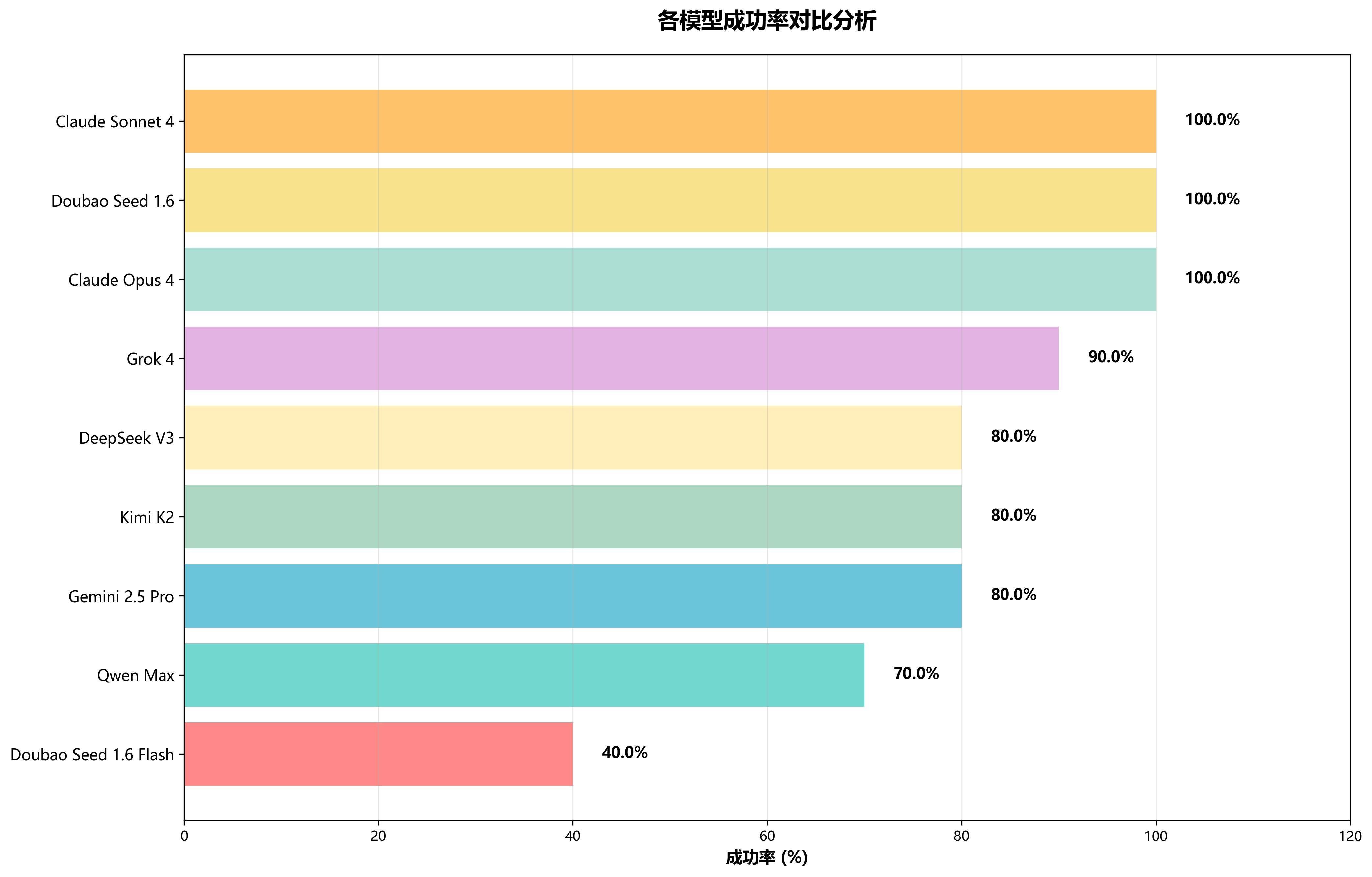
⏱️ 各模型执行时间对比分析
执行效率直接关系到用户体验质量。测试数据显示,Doubao Seed 1.6 Flash以其优化的架构在响应速度上领先群雄,平均执行时间仅需73秒。Claude系列在成功率上表现卓越,响应速度上也表现良好。Doubao Seed 1.6成功率满分,速度却相对较慢,这种差异反映了不同模型在速度与精度之间的权衡策略。
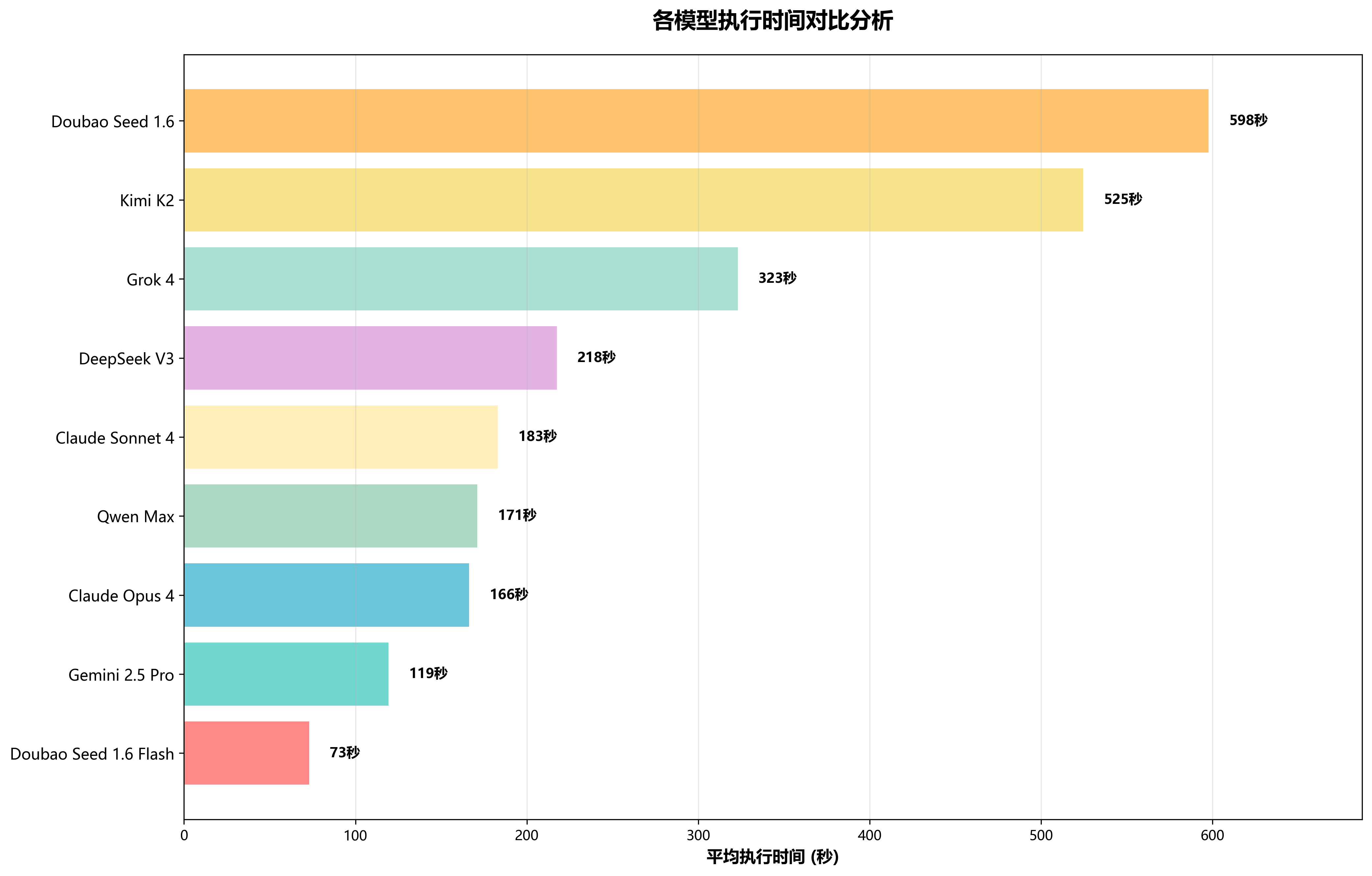
🔄 各模型执行轮数对比分析
执行轮数反映了模型的思维逻辑效率和任务理解能力。优秀的模型能够在更少的交互轮次中准确理解并完成复杂任务。从数据来看,Claude Sonnet 4凭借其强大的推理能力,在平均执行轮数上表现最优,仅需3.6轮即可完成大部分任务。Kimi K2交互轮数最多,平均需要6.8轮,展现了不同模型的分步骤处理和调错能力。
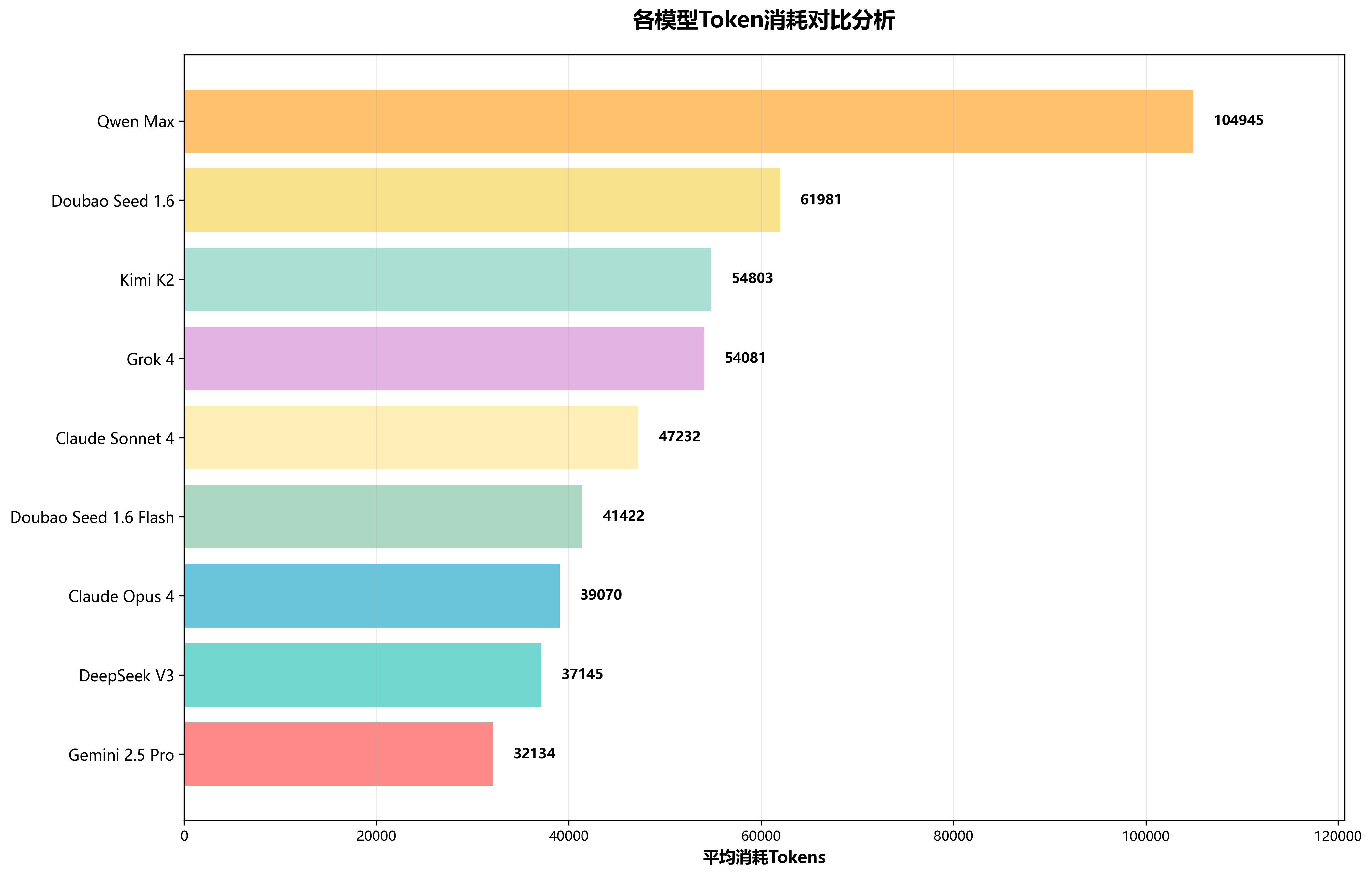
💰 各模型消耗Tokens对比分析
Tokens消耗直接影响使用成本,是企业级用户重要的考量因素。在本次评分体系中,我们首次将Tokens消耗纳入评估标准,更加重视成本效益。Gemini 2.5 pro和DeepSeek在Tokens消耗方面最节省。Qwen Max消耗较多,平均任务消耗约104945个tokens。
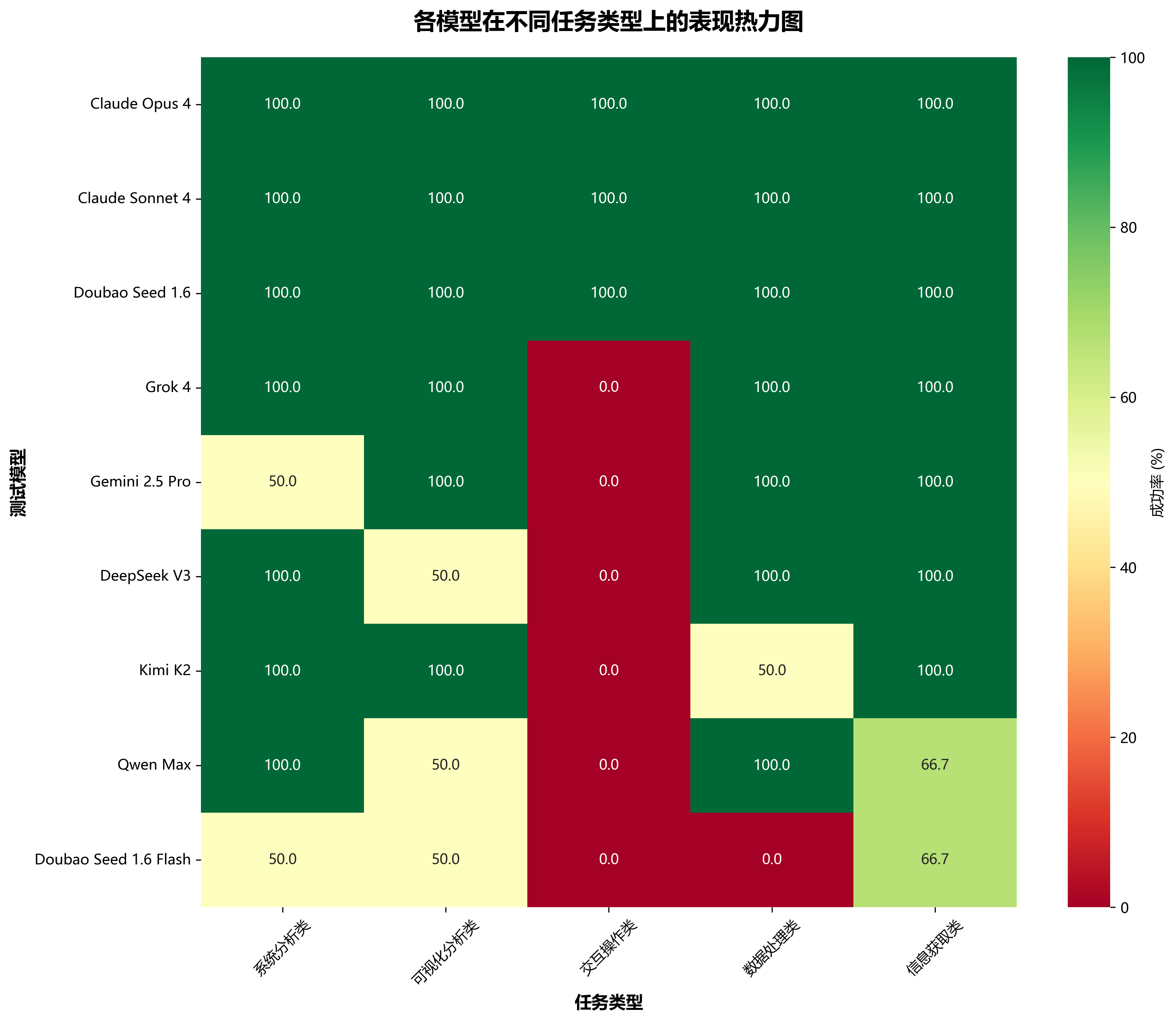
🔥 各模型在不同任务类型表现热力图
不同类型任务对模型能力的要求各异,热力图清晰展示了各模型的专业领域优势。Claude系列和Double Seed 1.6在综合能力上表现卓越,Grok系列在系统分析、可视化分析、数据处理和信息获取方面均表现良好,Gemini更擅长可视化分析、数据处理和信息获取任务,Kimi K2更擅长系统分析、可视化分析和信息获取类任务。交互操作类是本地智能体最看重的能力,仅Claude系列和Doubao Seed 1.6经受住挑战。
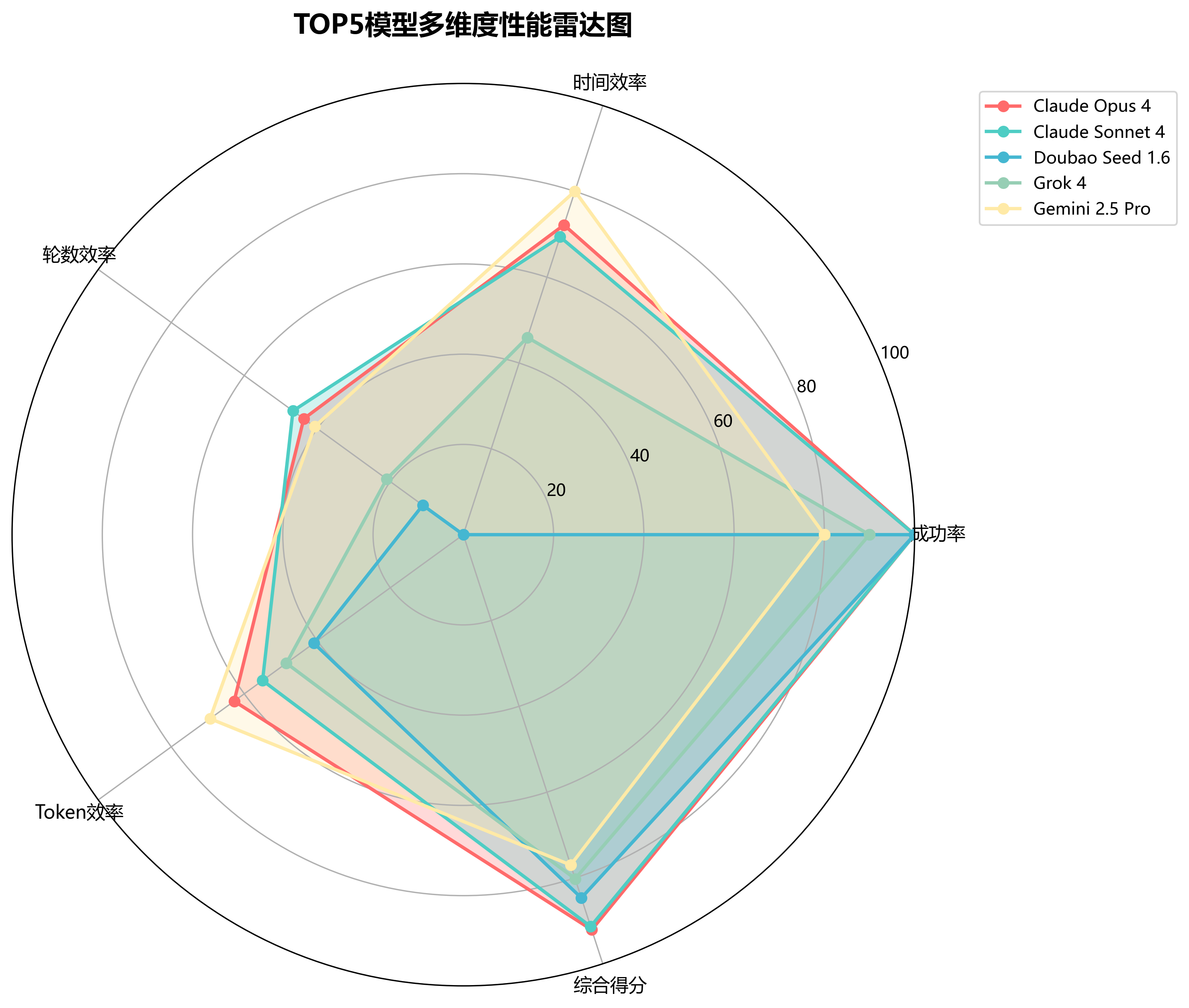
🎯 多维度性能雷达图
通过雷达图可以直观地观察各个顶尖模型在不同维度上的表现特征。Claude Opus 4在各维度上都保持了均衡的高水平表现,展现出全面发展的技术实力。其它模型则各有特色:Doubao在成功率方面优势明显,Gemini 2.5 Pro在时间效率和Tokens消耗方面表现良好。
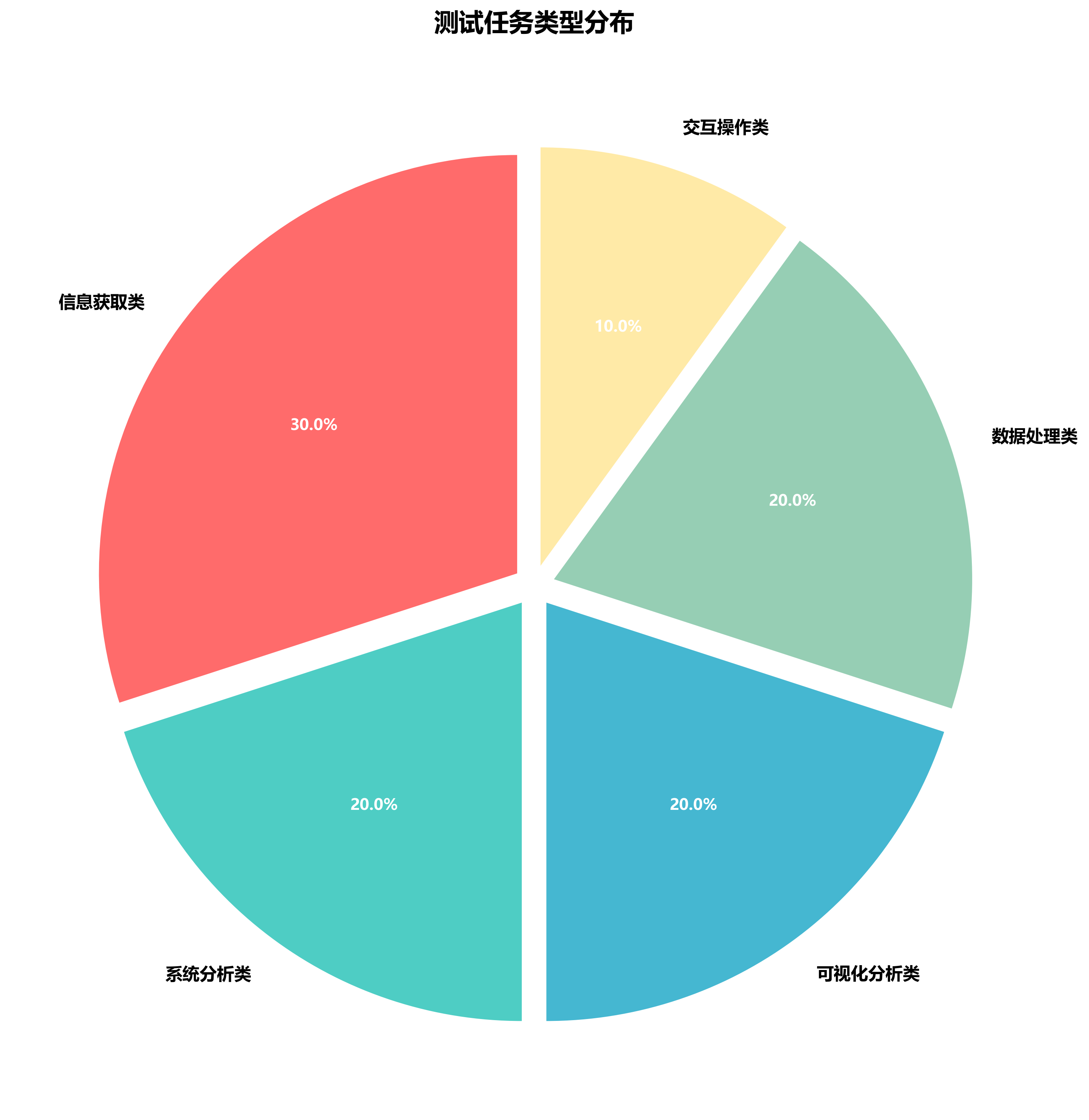
📊 测试任务类型分布
为确保测评的全面性和公平性,本次测试精心设计了涵盖五大应用场景的标准任务集。信息获取类任务占比最高(30%),反映了用户对智能搜索和知识查询的强烈需求。系统分析、可视化分析、数据处理类任务各占20%,体现了AI在专业工作场景中的重要作用。
💡 深度洞察
🏆 性能冠军:Claude Opus 4继续领跑群雄
Claude Opus 4以92.1分的综合得分稳居榜首,其100%的完美成功率和最优的执行轮数控制(3.8轮)展现了Anthropic在大模型技术方面的深厚积淀。特别在系统分析和复杂推理任务上,表现出了超越其它模型的理解能力和执行精度。
✨ 亮点发现:新星入围,格局更趋激烈
- Doubao Seed 1.6依然保持稳定的发挥,两次测评中均达到100%成功率,展现出极佳的稳定性
- Grok 4作为马斯克团队的力作,在创新性任务处理上表现亮眼,成功率达到90%,有望跻身前三
- Gemini 2.5 Pro在可视化分析任务中表现优异,体现了Google在多模态理解方面的技术优势
- Kimi K2作为新加入的模型,首次参评即获得69.5分,展现了月之暗面在大模型领域的技术积累
📈 改进建议:差异化发展策略
- 建议Kimi K2优化推理链路,减少不必要的执行轮数,提升用户交互体验
- Doubao Seed 1.6 Flash虽然速度领先,但在复杂任务成功率上仍有很大提升空间,建议加强模型训练
- Qwen Max可通过优化算法架构进一步提升在复杂推理任务上的表现
- 各模型可考虑针对特定应用场景进行垂直优化,发挥各自技术特色
❌ 失败原因分析
通过对失败案例的深入分析,我们发现模型失败主要集中在以下几个方面。理解这些失败模式有助于模型开发者明确优化方向。
- "代码质量问题" - 出现6次,占失败案例的37.5%
- "代码块标记不遵循提示词问题" - 出现2次,占失败案例的12.5%
- "没有自主决策方案" - 出现2次,占失败案例的12.5%
- "任务异常中断" - 出现2次,占失败案例的12.5%
- "风险问题拒绝" - 出现2次,占失败案例的12.5%
- "拒绝执行" - 出现2次,占失败案例的12.5%
📋 测试任务分类表
以下展示本次测评使用的核心标准任务样本,这些任务经过精心设计,覆盖了AI助手在实际应用中的主要场景。每个任务均具备明确的评价标准,确保测评结果的客观性和可重复性。
| 序号 | 测试问题 | 任务类型 |
|---|---|---|
| 1 | 分析一下我浏览器的收藏夹和历史访问记录,看看我是一个什么样的人? | 系统分析类 |
| 2 | 帮我推荐10个今天需要关注的股票,把他们的涨跌情况,做成漂亮的html报表写到"gp.html" | 可视化分析类 |
| 3 | 打开windows系统默认画图软件,控制我鼠标,帮我化一个身材优美的铅笔画女性。 | 交互操作类 |
| 4 | 从世界银行获取中国gdp最近60年数据,帮我分析关键转折点,最后帮我画一个折线图,标记关键转折点和原因 | 可视化分析类 |
| 5 | 我有一个10年的打卡记录csv表,有姓名 日期 上班时间 下班时间 几列。帮我生成一个1000人(帮我取下名字),从2020年至今的每个工作日的模拟测试数据。然后帮我统计10个奋斗者,和10个末尾淘汰建议人员,帮我画成柱状图。 | 数据处理类 |
| 6 | 分析一下我电脑桌面的文件和应用类型,针对混乱的文件或应用根据类型做个详细整理建议放到精美的html中 | 系统分析类 |
| 7 | XXX是我的网站访问日志文件,第6个字段为客户端IP,第10个字段为访问URL,请帮我分析下日志中请求量最高的前5个URL及客户端IP并统计出具体的数量,将结果做成漂亮的分析报告保存为“log.html”。 | 数据处理类 |
| 8 | 今天天气怎么样? | 信息获取类 |
| 9 | 查询最新的AI相关新闻 | 信息获取类 |
| 10 | 把百度首页的热搜标题爬下来 | 信息获取类 |
🚀 测评总结
核心发现
- Claude系列确立技术领先地位:Claude Opus 4和Claude Sonnet 4分别以92.1分和91.3分占据前两名,展现了Anthropic在大模型领域的技术实力
- 中国模型表现亮眼:Doubao Seed 1.6以84.6分稳居季军,Qwen Max首次参评获得60.5分,DeepSeek V3和Kimi K2也展现了不俗实力,体现了中国AI技术的快速发展
- 成本效益成为关键考量:在保证质量的前提下,Token消耗和执行效率日益成为企业级用户的重要选择标准
- 垂直领域特色明显:各模型在不同任务类型上表现出差异化优势,为细分应用场景提供了更精准的选择依据
技术成熟度分析
本次测评整体成功率达到82.2%,新增模型的加入使得平均水平略有上涨,头部模型依然保持100%成功率,展现了技术领先优势。国产模型在追赶过程中表现出强劲的发展势头。
性能稳定性分析
通过对9个模型执行时间、轮数和Token消耗的标准差分析,Claude Opus 4在性能稳定性方面表现最佳,Doubao系列在成功率上有显著优势。
商业化适用性分析
综合考虑性能与成本,Doubao Seed 1.6展现出最佳的商业化部署潜力。在保证100%成功率基础上,成本消耗优势明显。
创新能力评估
Grok 4在创新性和复杂推理任务上表现突出,虽然整体排名第四,但在特定场景下具备独特优势。
用户体验分析
平均5.0轮的执行轮数表明多数模型已具备良好的任务理解能力。Claude系列在一次性任务完成率上领先,提供了更流畅的交互体验。新加入的模型在学习用户意图方面还有进步空间。
成本效益权衡
此次测评增加的新锐模型表现良好,为垂直领域应用业务的用户提供了重要参考,用户可根据需求类型选择最适合的高性价比模型。