🚀AiPy大模型适配度测评第三期报告
📋背景说明
为帮助AiPy用户精准把握AI技术前沿,享受最佳的AI体验,我们持续追踪全球大语言模型的技术演进与性能表现,本次迎来第三次模型测评。 本次评测聚焦最新发布的旗舰模型,纳入通义千问三连发的Qwen3系列(含Thinking-2507深度推理版、Instruct-2507高效指令版、Coder-Plus专业编程版) 与智谱华章的GLM-4.5开源模型,同时对比OpenAI GPT-4.1、Google Gemini-2.5 Pro等海外顶级产品,覆盖13款国内外模型, 首次实现国产与海外阵营的差异化对比分析,为用户挑选最适配的LLM模型提供参考。
🔍测评亮点
- 覆盖13款国内外主流大模型,包含最新Qwen3系列、GLM-4.5
- 130项真实任务测试,涵盖5大应用场景
- 多维度评估:成功率、执行时间、Tokens消耗
- 国产vs海外模型差异化对比分析
📊测试概况
本次测评在严格控制变量的条件下,对13款主流大模型进行了全面测试。通过130项标准化任务, 深入评估各模型在实际应用场景中的表现,为用户选型提供客观数据支撑。
测试模型数
平均执行时间
平均消耗Tokens
整体成功率
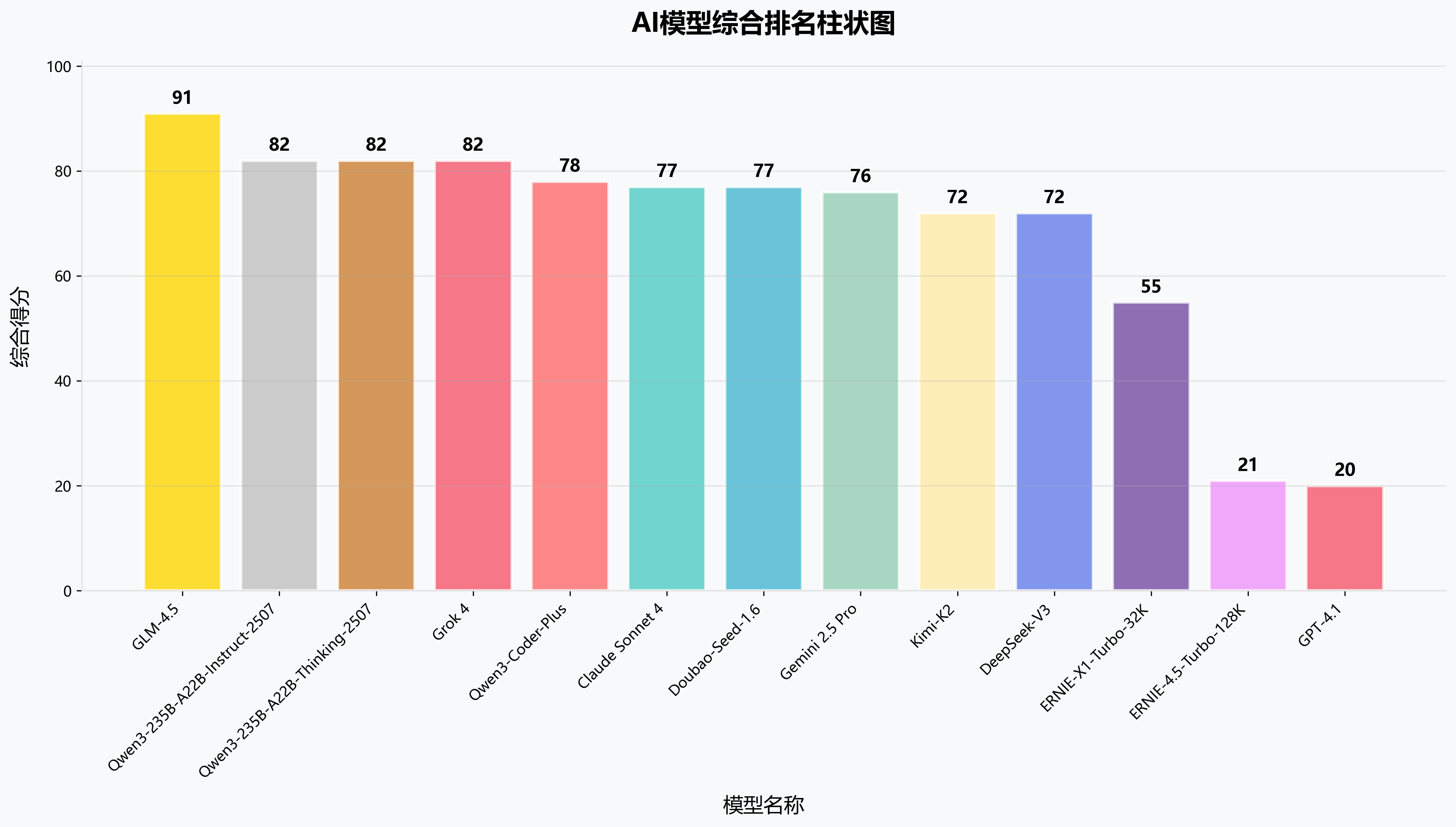
🏆综合排名
基于成功率(权重80%)、Tokens效率(权重10%)、时间效率(权重10%)的综合评估体系, 呈现各模型的整体实力排名。GLM-4.5凭借完美成功率夺得桂冠,Qwen3系列表现亮眼包揽2-3名。值得注意的是,本次测评前三名均为国产模型!
| 排名 | 模型名称 | 成功率 | 平均执行时间 | 平均消耗Tokens | 综合得分 | 模型厂商 | 地区 |
|---|---|---|---|---|---|---|---|
| 🥇1 | GLM-4.5 | 100% | 294s | 59912 | 91 | 智谱华章 | |
| 🥈2 | Qwen3-235B-A22B-Instruct-2507 | 90% | 173s | 86248 | 82 | 阿里 | |
| 🥉3 | Qwen3-235B-A22B-Thinking-2507 | 90% | 370s | 51501 | 82 | 阿里 | |
| 4 | Grok 4 | 90% | 353s | 59611 | 82 | xAI | |
| 5 | Qwen3-Coder-Plus | 90% | 253s | 119416 | 78 | 阿里 | |
| 6 | Claude Sonnet 4 | 90% | 389s | 102025 | 77 | Anthropic | |
| 7 | Doubao-Seed-1.6 | 90% | 617s | 62787 | 77 | 字节跳动 | |
| 8 | Gemini 2.5 Pro | 80% | 112s | 30128 | 76 | ||
| 9 | Kimi-K2 | 80% | 526s | 49189 | 72 | 月之暗面 | |
| 10 | DeepSeek-V3 | 70% | 143s | 32318 | 72 | 深度求索 | |
| 11 | ERNIE-X1-Turbo-32K | 60% | 530s | 54007 | 55 | 百度 | |
| 12 | ERNIE-4.5-Turbo-128K | 20% | 320s | 117106 | 21 | 百度 | |
| 13 | GPT-4.1 | 0% | 22s | 4182 | 20 | OpenAI |
国内模型排名情况
国产大模型整体表现优异,9款参测模型中有6款成功率达到80%以上。GLM-4.5以完美表现领跑, 阿里Qwen3系列紧随其后,显示出国产AI技术的强劲实力和快速发展势头。字节跳动、月之暗面、深度求索等新兴厂商也展现出不俗的技术实力, 而老牌厂商百度的两款模型表现分化明显,反映出技术迭代的重要性。
🌟国内模型亮点
- GLM-4.5实现100%成功率,综合得分91分领跑全场
- Qwen3系列包揽国内2-4名,展现阿里AI技术深度
- 字节豆包Seed-1.6表现略有下降,综合排名位列国内第5
- 百度两款模型在此次测评中均处于垫底状态
| 国内排名 | 模型名称 | 成功率 | 综合得分 | 模型厂商 |
|---|---|---|---|---|
| 🥇1 | GLM-4.5 | 100% | 91 | 智谱华章 |
| 🥈2 | Qwen3-235B-A22B-Instruct-2507 | 90% | 82 | 阿里 |
| 🥉3 | Qwen3-235B-A22B-Thinking-2507 | 90% | 82 | 阿里 |
| 4 | Qwen3-Coder-Plus | 90% | 78 | 阿里 |
| 5 | Doubao-Seed-1.6 | 90% | 77 | 字节跳动 |
| 6 | Kimi-K2 | 80% | 72 | 月之暗面 |
| 7 | DeepSeek-V3 | 70% | 72 | 深度求索 |
| 8 | ERNIE-X1-Turbo-32K | 60% | 55 | 百度 |
| 9 | ERNIE-4.5-Turbo-128K | 20% | 21 | 百度 |
国外模型排名情况
海外模型阵营表现分化明显,xAI的Grok 4和Google的Gemini 2.5 Pro表现优秀, 而传统巨头OpenAI的GPT-4.1意外垫底,显示出大模型竞争格局的快速变化。Claude Sonnet 4在综合性能上保持竞争力, 但在某些特定任务上仍存在改进空间,反映出海外厂商在适应中文环境和特定应用场景方面仍有挑战。
🌍国外模型分析
- Grok 4以90%成功率领跑海外阵营,超越Claude
- Claude Sonnet 4在复杂任务处理上展现优势,虽本次相比上次测评略有下降,仍保持优秀水平
- Gemini 2.5 Pro时间效率突出,111.6秒平均执行时间最短
- GPT-4.1表现不佳,存在代码块标记等技术问题,成功率为0暴漏致命问题
| 海外排名 | 模型名称 | 成功率 | 综合得分 | 模型厂商 |
|---|---|---|---|---|
| 🥇1 | Grok 4 | 90% | 82 | xAI |
| 🥈2 | Claude Sonnet 4 | 90% | 77 | Anthropic |
| 🥉3 | Gemini 2.5 Pro | 80% | 76 | |
| 4 | GPT-4.1 | 0.0% | 20 | OpenAI |
📈各模型成功率对比分析
成功率是衡量模型实用性的核心指标,直接反映模型在实际应用中的可靠性。 从测试结果看,GLM-4.5以100%成功率一骑绝尘,多款模型达到90%的优秀水平。成功率的分化反映出不同模型在技术成熟度、 指令理解能力、代码生成质量等方面存在显著差异,这也为用户选择提供了重要参考依据。
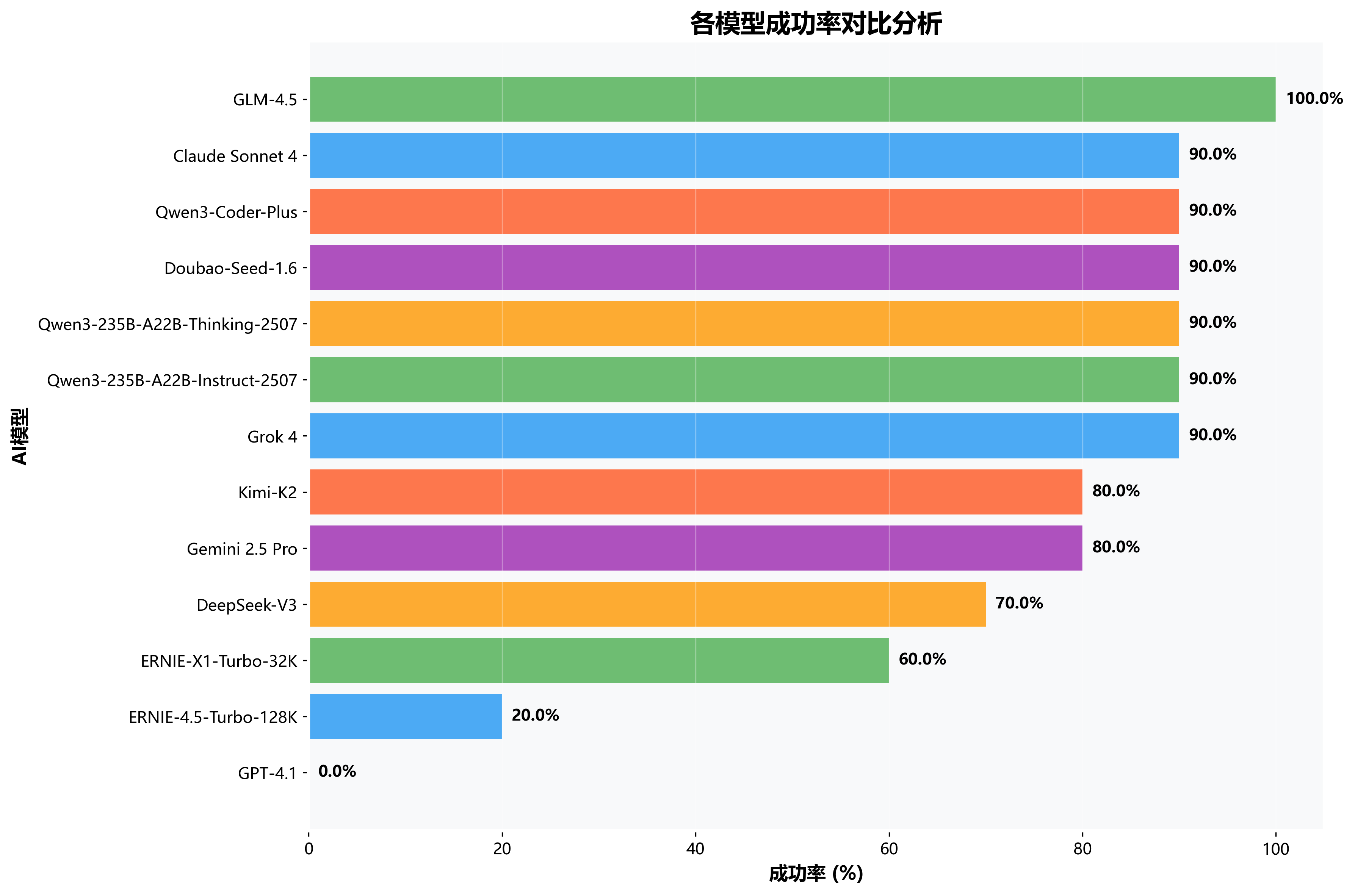
💡成功率关键发现
- GLM-4.5独占鳌头:100%成功率,零失败记录
- 90%俱乐部:6款模型成功率达到90%,竞争激烈
- 分化明显:最高100%与最低0%形成巨大差距
- 国产优势:前5名中有3款为国产模型
⏱️各模型执行时间对比分析
执行时间直接影响用户体验,特别是在实时交互场景中更为关键。除掉成功率为0的GPT-4.1, Gemini 2.5 Pro以111.6秒的平均执行时间领跑,显示出谷歌在推理效率优化方面的技术优势。值得注意的是, 部分高成功率模型在执行时间上也保持了良好的平衡,如GLM-4.5和Qwen3-Instruct,这种效率与准确性的平衡是评判模型实用性的重要标准。
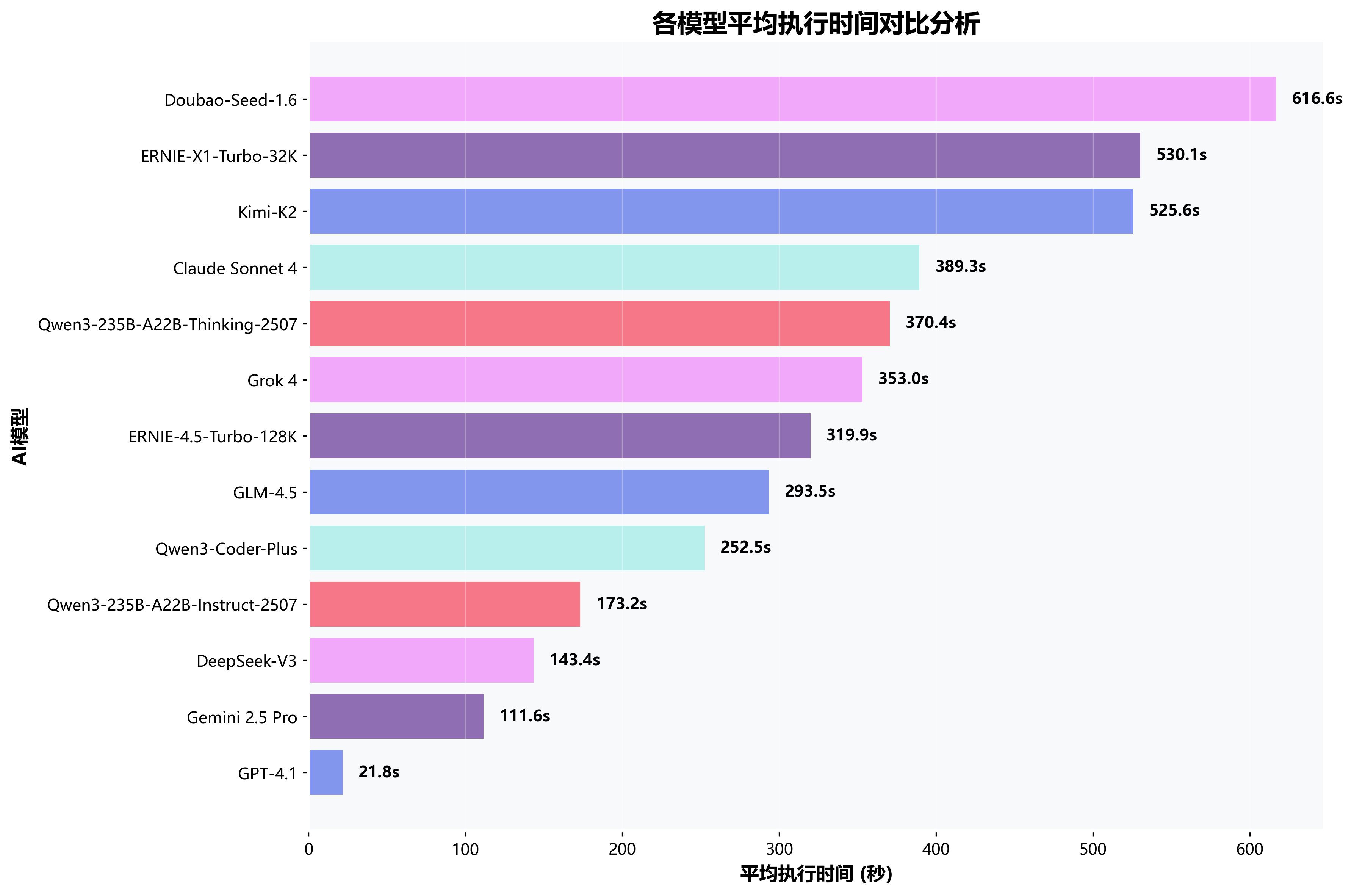
⚡执行效率洞察
- 效率冠军:Gemini 2.5 Pro平均111.6秒,响应最快
- 速度阶梯:DeepSeek-V3、Qwen3-Instruct紧随其后
- 差距显著:最快与最慢相差5倍以上时间
- 均衡表现:多数模型集中在200-400秒区间
💰各模型消耗Tokens对比分析
Tokens消耗直接关系到使用成本,是企业级应用中的重要考量因素。 GPT-4.1虽然成功率低,但Tokens消耗最少,而一些模型存在过度消耗现象。理想的模型应该在保证高成功率的同时, 控制合理的资源消耗,GLM-4.5和DeepSeek-V3在这方面表现出了良好的成本效益比,为不同预算需求的用户提供了选择空间。
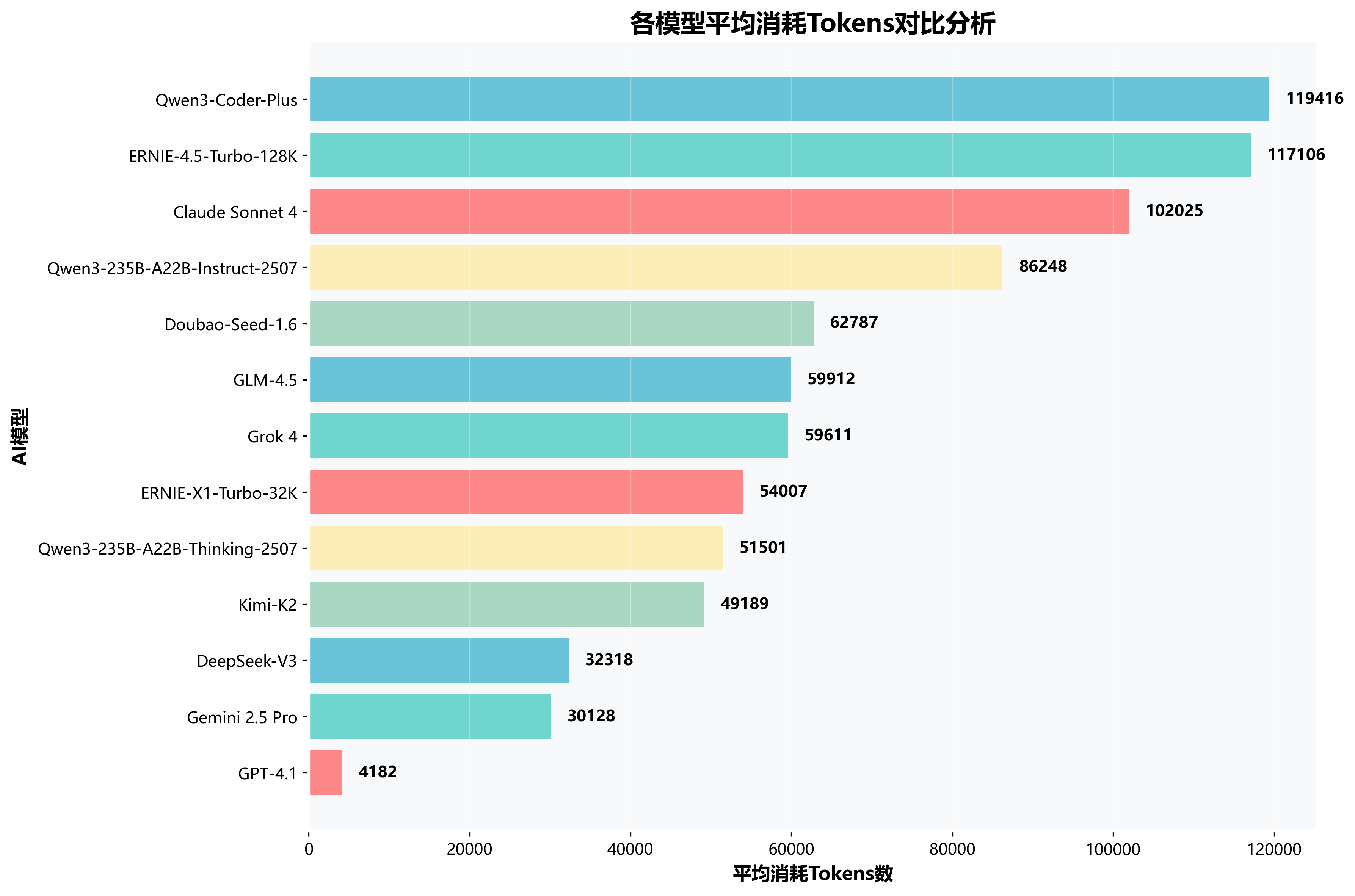
💎成本效率分析
- 最省成本:GPT-4.1仅消耗4,182 tokens,但成功率为0
- 性价比王:DeepSeek-V3成本控制优秀,仅32,318 tokens
- 高消耗群:Qwen3-Instruct、Claude等超过10万tokens
- 均衡典型:GLM-4.5在高成功率下保持适中消耗
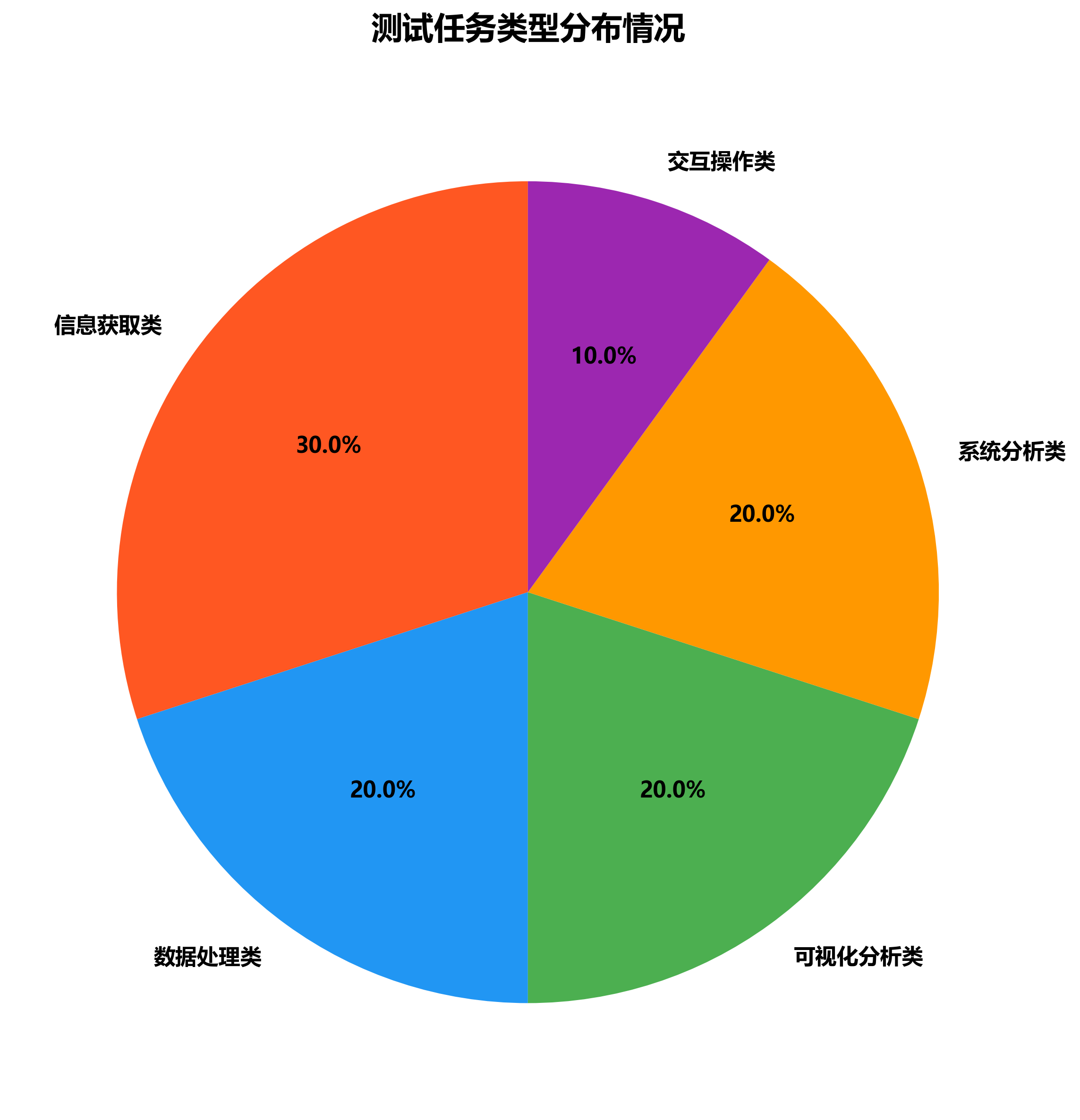
📊测试任务类型分布情况
本次测评涵盖5大核心应用场景,全面考察模型的综合能力。 信息获取类任务占比最高,反映了用户对AI获取和处理信息能力的重视。各任务类型的均衡分布确保了测评的全面性和代表性, 能够真实反映模型在不同应用场景下的实际表现,为用户根据具体需求选择合适模型提供了科学依据。
🔥各模型在不同任务类型表现分析
通过热力图深入分析各模型在5大任务类型中的具体表现,揭示每款模型的优势领域和短板所在。 GLM-4.5在所有任务类型中都保持了优秀表现,而部分模型在特定领域展现出专业化优势。这种差异化表现为用户根据具体应用场景 选择最适合的模型提供了重要参考,同时也反映出当前大模型技术发展中专业化与通用性并存的趋势。
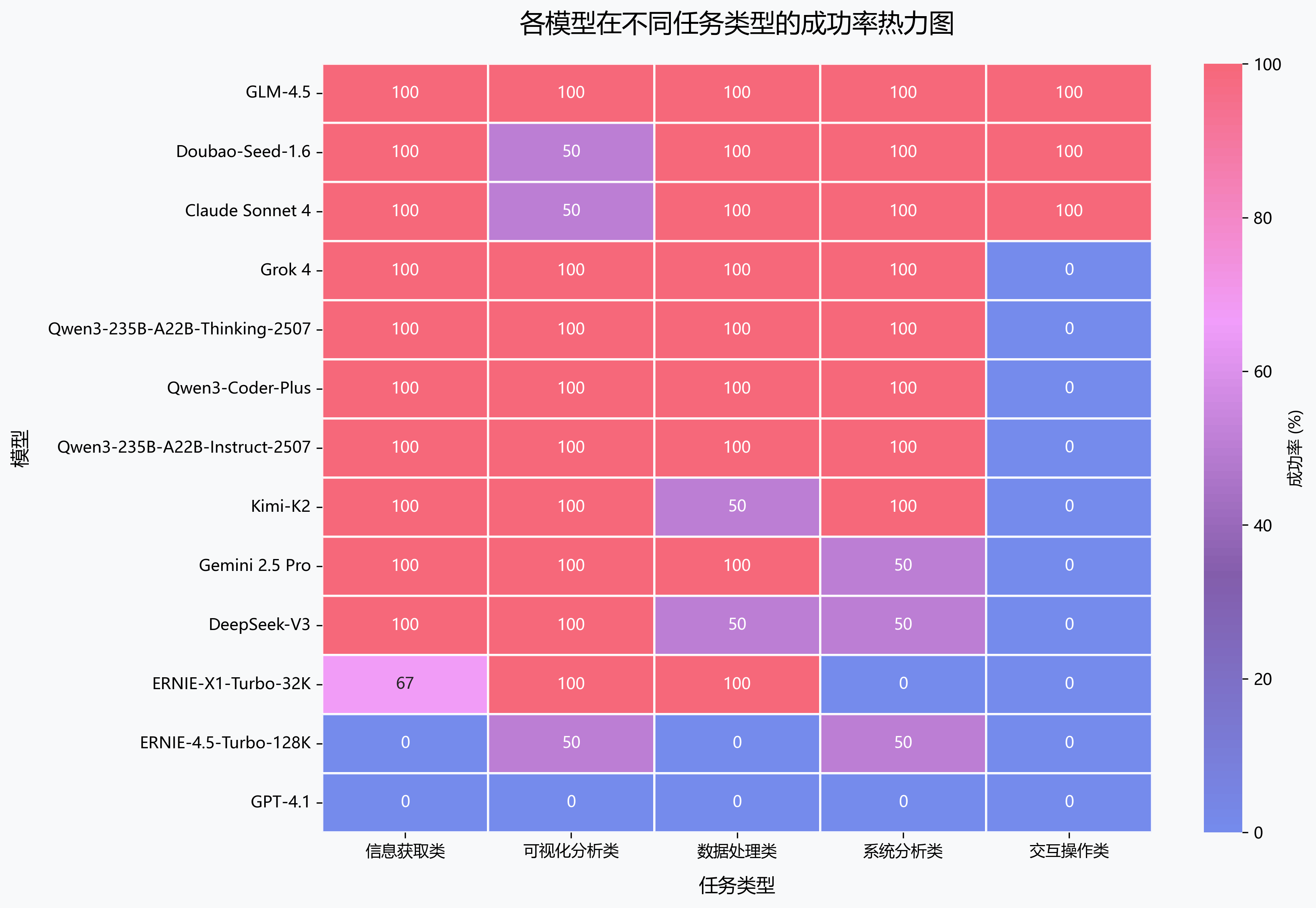
🎯任务类型表现洞察
- 全能冠军:GLM-4.5在所有类型任务中表现优异
- 信息获取强者:多数模型在信息获取类任务表现突出
- 交互操作挑战:交互操作类是最具挑战性的任务类型
- 专业化趋势:部分模型在特定领域展现专业优势
🕸️多维度性能雷达图
通过雷达图直观展示前6名模型在成功率、时间效率、成本效率、综合得分、稳定性等5个维度的综合表现, 帮助用户根据具体需求选择最适合的模型。每个模型都展现出独特的性能特征,用户可根据自身对不同维度的重视程度, 选择最匹配自身需求的AI助手,实现效果与成本的最佳平衡。
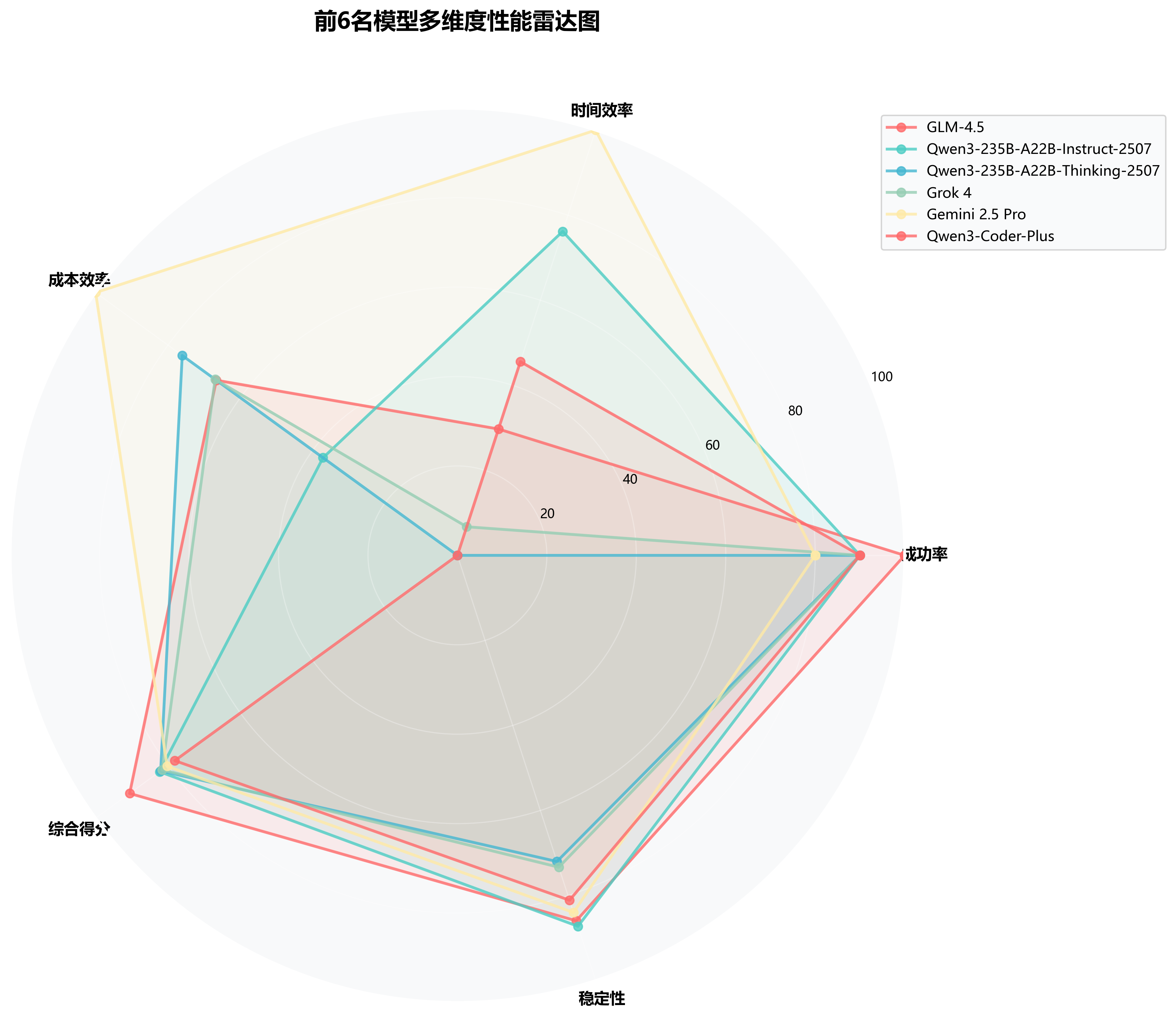
🎯多维度分析
- 全能王者:GLM-4.5各维度均衡,综合实力最强
- 效率专家:Gemini 2.5 Pro在时间效率上独树一帜
- 稳定可靠:Qwen3系列在多维度保持稳定高水平
- 特色鲜明:每个模型都有自己的优势领域
❌失败原因分析
通过深入分析34次失败案例,识别出模型的主要问题点,为模型优化提供方向。 代码块标记问题是最主要的失败原因,占比达到29.4%。这些失败案例的分析不仅帮助我们理解当前大模型的技术瓶颈, 也为模型开发商提供了明确的改进方向,同时提醒用户在实际应用中需要关注的潜在风险点。
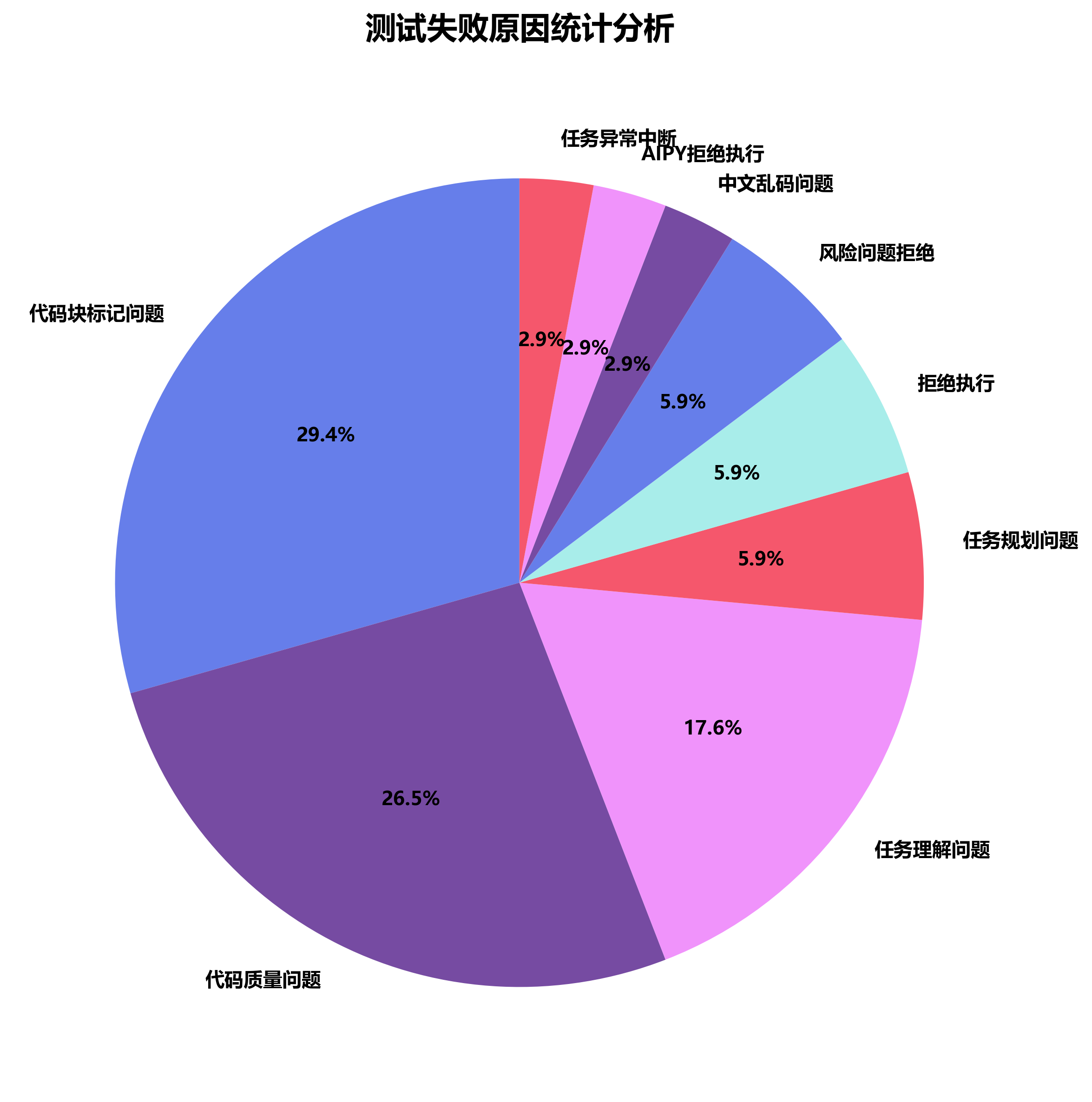
🔍失败原因深度剖析
- 代码块标记问题(29.4%):主要集中在GPT-4.1,技术规范理解有待提升
- 代码质量问题(26.5%):生成代码存在逻辑错误或执行异常
- 任务理解问题(17.6%):对复杂任务的意图把握不够准确
- 其他问题(26.5%):包括任务规划、拒绝执行、中文乱码等问题
📝测试任务分类表
展示本次测评使用的核心测试任务样例,涵盖信息获取、数据处理、可视化分析、系统分析、交互操作等多个维度, 确保测评的全面性和代表性。这些任务的设计充分考虑了实际应用场景的需求,能够有效检验模型在真实工作环境中的表现能力, 为用户提供贴近实际使用情况的性能参考。
| 序号 | 测试任务 | 任务类型 |
|---|---|---|
| 1 | 把百度首页的热搜标题爬下来 | 信息获取类 |
| 2 | 查询最新的AI相关新闻 | 信息获取类 |
| 3 | 今天天气怎么样? | 信息获取类 |
| 4 | XXX是我的网站访问日志文件,第6个字段为客户端IP,第10个字段为访问URL,请帮我分析下日志中请求量最高的前5个URL及客户端IP并统计出具体的数量,将结果做成漂亮的分析报告保存为“log.html”。 | 数据处理类 |
| 5 | 我有一个10年的打卡记录csv表,有姓名 日期 上班时间 下班时间 几列。帮我生成一个1000人(帮我取下名字),从2020年至今的每个工作日的模拟测试数据。然后帮我统计10个奋斗者,和10个末尾淘汰建议人员,帮我画成柱状图。 | 数据处理类 |
| 6 | 从世界银行获取中国gdp最近60年数据,帮我分析关键转折点,最后帮我画一个折线图,标记关键转折点和原因 | 可视化分析类 |
| 7 | 打开windows系统默认画图软件,控制我鼠标,帮我化一个身材优美的铅笔画女性。 | 交互操作类 |
| 8 | 帮我推荐10个今天需要关注的股票,把他们的涨跌情况,做成漂亮的html报表写到"gp.html" | 可视化分析类 |
| 9 | 分析一下我电脑桌面的文件和应用类型,针对混乱的文件或应用根据类型做个详细整理建议放到精美的html中 | 系统分析类 |
| 10 | 分析一下我浏览器的收藏夹和历史访问记录,看看我是一个什么样的人? | 系统分析类 |
💡深度洞察
🎖️性能冠军
综合冠军:GLM-4.5
- 本次测评唯一实现100%成功率的模型,零失败记录
- 综合得分91分,领先第二名将近10分
- 在复杂任务处理上展现出色稳定性
- 代表国产大模型技术新高度
效率冠军:Gemini 2.5 Pro
- 平均执行时间仅111.6秒,效率领跑
- 在保持80%成功率的同时实现最快响应
- Tokens消耗控制在中等水平,性价比突出
✨亮点发现
🚀国产模型崛起
- 前3名均为国产模型,展现国产模型在AI技术领域的快速崛起
- Qwen3系列集体发力,包揽2、3、5名
- 在数据处理和系统分析任务上优势明显
- 技术迭代速度快,版本间差异显著
📊技术分化明显
- 成功率分化:从100%到0%跨度极大
- 效率差异:最快与最慢相差5倍以上
- 成本悬殊:最高与最低tokens消耗差100倍
- 专业化趋势:不同模型在特定领域各有所长
🔧改进建议
🎯针对模型开发商
- 加强代码块标记规范的理解和执行
- 提升复杂任务的规划和分解能力
- 优化中文字符处理,避免乱码问题
- 平衡功能完成度与资源消耗的关系
💼针对用户选型
- 追求稳定性:优选GLM-4.5等高成功率模型
- 注重效率:考虑Gemini 2.5 Pro等快速响应模型
- 成本敏感:关注DeepSeek-V3等低消耗模型
- 场景匹配:根据具体应用需求选择特色模型
📄测评总结
本次AiPy第三期大模型测评涵盖13款国内外主流产品,通过130项标准化任务的全面评估, 呈现出当前大模型技术发展的新格局和新趋势。这次测评不仅见证了国产AI技术的快速崛起, 也揭示了全球大模型竞争格局的深刻变化。
🎯核心结论
- 国产强势崛起:GLM-4.5夺冠,Qwen3系列集体发力,国产模型整体实力显著提升
- 技术分化加剧:模型间性能差距扩大,专业化发展趋势明显
- 实用性为王:成功率成为核心竞争力,稳定性比单项优势更重要
- 效率成新战场:在保证准确性前提下,响应速度和成本控制成为差异化优势
从本次测评结果可以看出,大模型技术正进入一个新的发展阶段。国产模型在技术实力上已经能够与国际顶级产品分庭抗礼, 甚至在某些方面实现了超越。GLM-4.5的完美表现证明了国产AI技术的成熟度,而Qwen3系列的集体优异表现则展示了 中国AI企业在技术创新方面的持续投入和快速迭代能力。
同时,我们也观察到海外模型在效率优化和特定场景应用方面仍具备一定优势,这提醒我们技术竞争的多元化特征。 未来的发展中,只有在准确性、效率性、经济性等多个维度实现均衡发展,才能在激烈的市场竞争中脱颖而出。
🔮未来展望
基于本次测评结果,我们预测未来大模型发展将呈现以下趋势:
- 技术门槛持续提高:基础功能实现已成为入门标准,高级应用能力成为核心竞争力
- 成本效益成关键:在功能同质化趋势下,性价比将成为用户选择的决定性因素
- 专业化与通用性并重:既要保持通用能力,又要在特定领域形成差异化优势
- 生态建设重要性凸显:单一模型竞争转向生态体系竞争
- 用户体验决定成败:技术指标优化最终要转化为用户体验的提升
对于企业用户而言,如何在众多优秀模型中选择合适的AI助手,需要综合考虑技术性能、成本预算、应用场景等多重因素。 本报告提供的多维度评估数据,为用户提供了科学的决策依据。我们建议用户在选择时不仅要关注排名,更要结合自身实际需求, 选择最适配的技术方案。
AiPy将持续追踪大模型技术发展,定期更新测评数据,为用户提供最新、最客观的技术评估, 助力每一位用户在AI时代找到最适合的技术伙伴,共同迎接智能化未来的无限可能。