🚀 AiPy大模型适配度测评第四期报告
📊 基于AiPy Pro v0.7.2 Windows客户端
📅 发布时间:2025年08月15日
📋 背景说明
经过前三期标准任务的测评,主流大模型在AiPy的基础功能适配度方面已得到基本验证。为进一步贴近实际应用场景,本次测评对原有测评任务进行了全面升级,重点覆盖了十大核心能力维度,从数据深度分析、多样化内容生成,到Word文档高效处理、实用工具自主构建;既包含批处理文件执行、MCP调用协同、图表可视化制作,也涉及本地软件控制、表格数据精细化处理;同时纳入联网信息整合、网络数据爬取,以及大文件处理与报告生成等实用场景,全方位评估模型的实战适配性。本次测评采用更加严格的评估标准,通过加权计算法和修正均值法保障数据的科学性和可靠性,为用户选择最适合的AI助手提供更加精准的参考依据。
🎯 测试概况
测试模型数
12个
平均测试时间
263秒
平均消耗Tokens
56242个
整体成功率
56%
🏆 综合排名
本次综合评分采用科学的加权计算法和修正均值法,通过这一优化的评分体系,我们能够更准确地衡量每个模型在实际应用中的综合表现,为用户提供更加客观和可靠的选择参考。
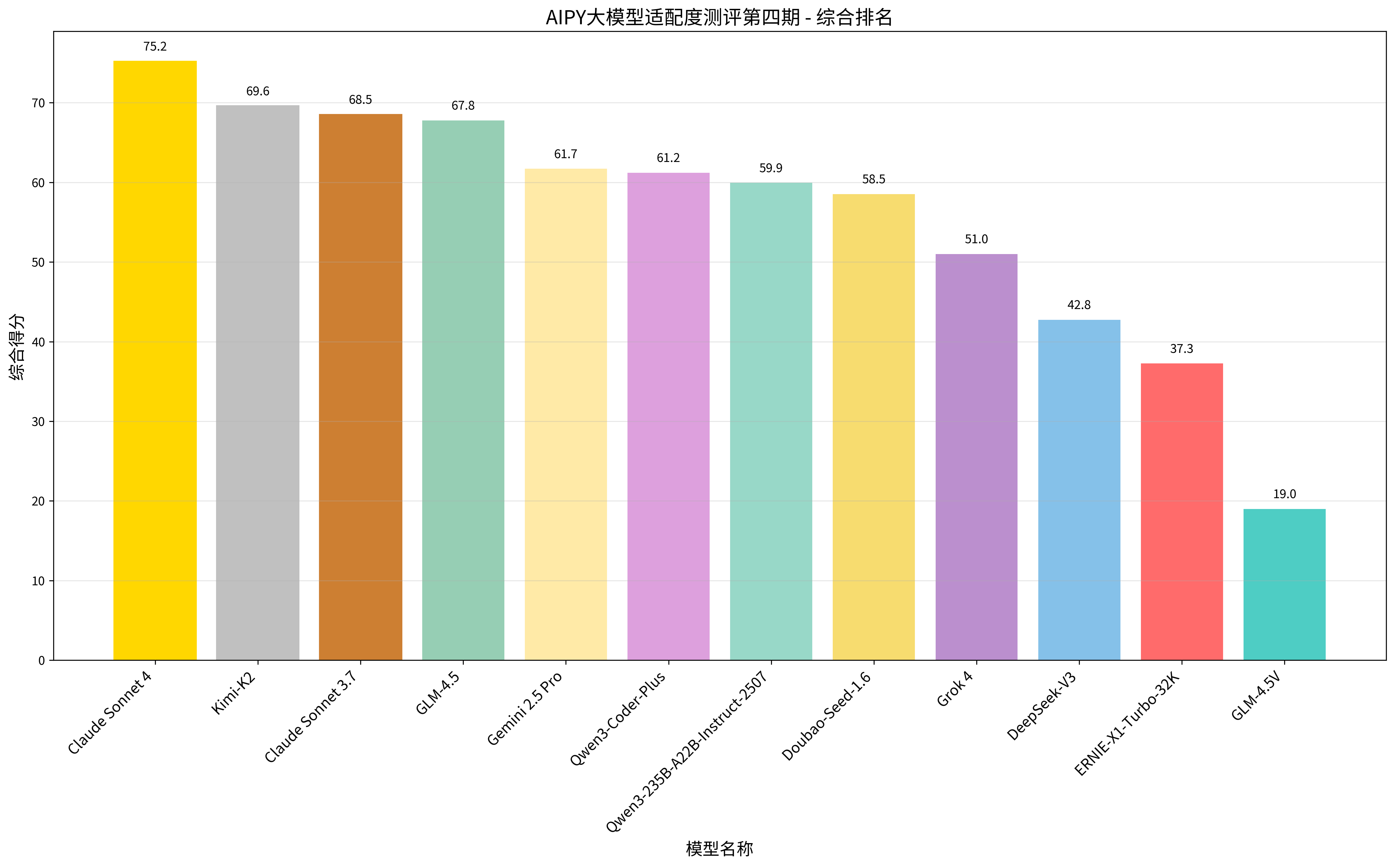
经综合计算,在本次难度提升,场景覆盖更全的测评用例下,排名较往期测评发生较大变化,呈现明显的梯队分化,Anthropic 的 Claude 系列表现突出,Claude Sonnet 4 以 80% 的成功率、75 分的综合得分位居榜首;月之暗面的 Kimi-K2和 Anthropic 的 Claude Sonnet 3.7列二、三位,上期冠军的GLM-4.5则降至第四名。
| 排名 | 模型名称 | 成功率 | 平均执行时间 | 平均消耗Tokens | 综合得分 | 模型厂商 | 地区 |
|---|---|---|---|---|---|---|---|
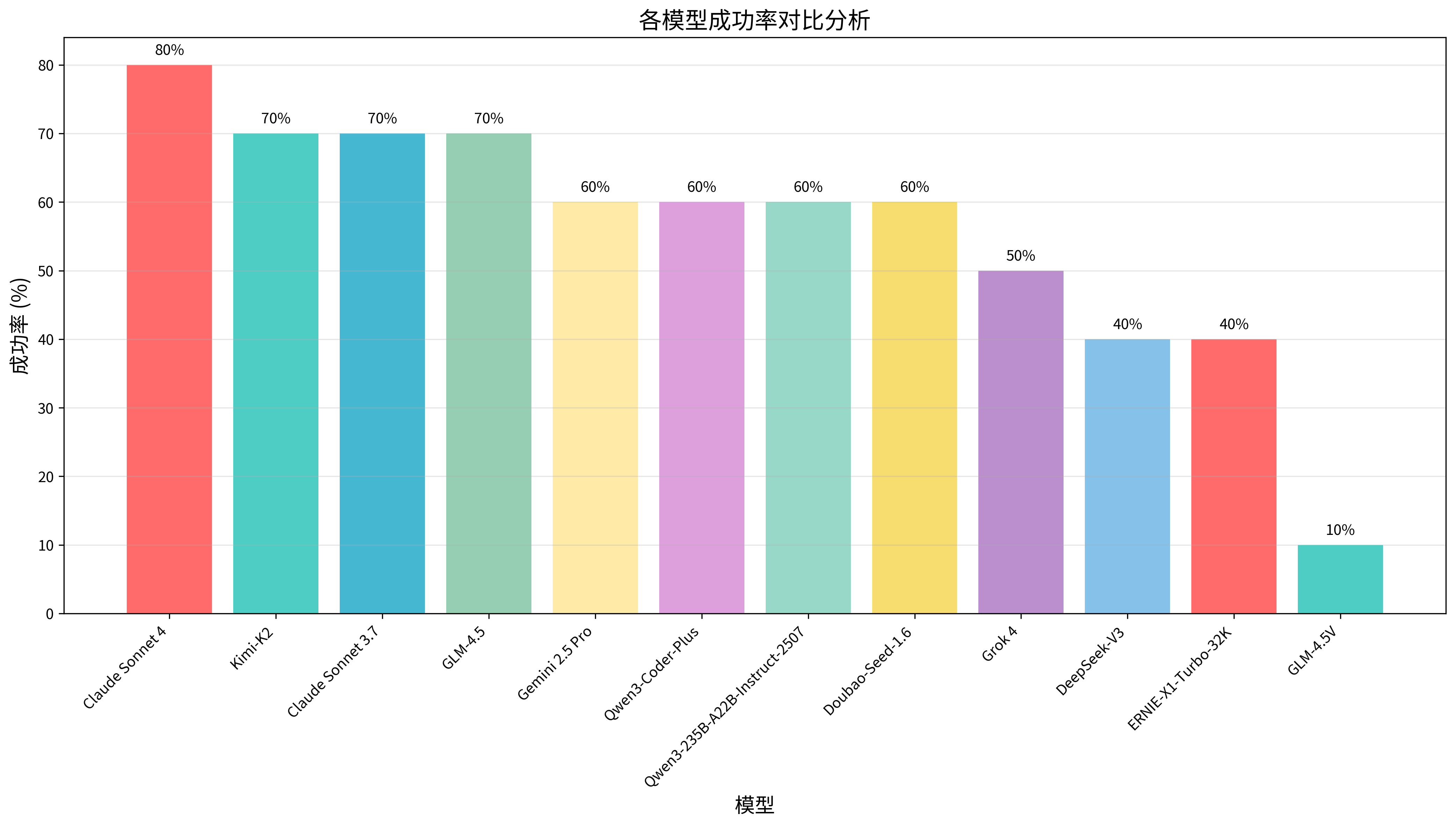
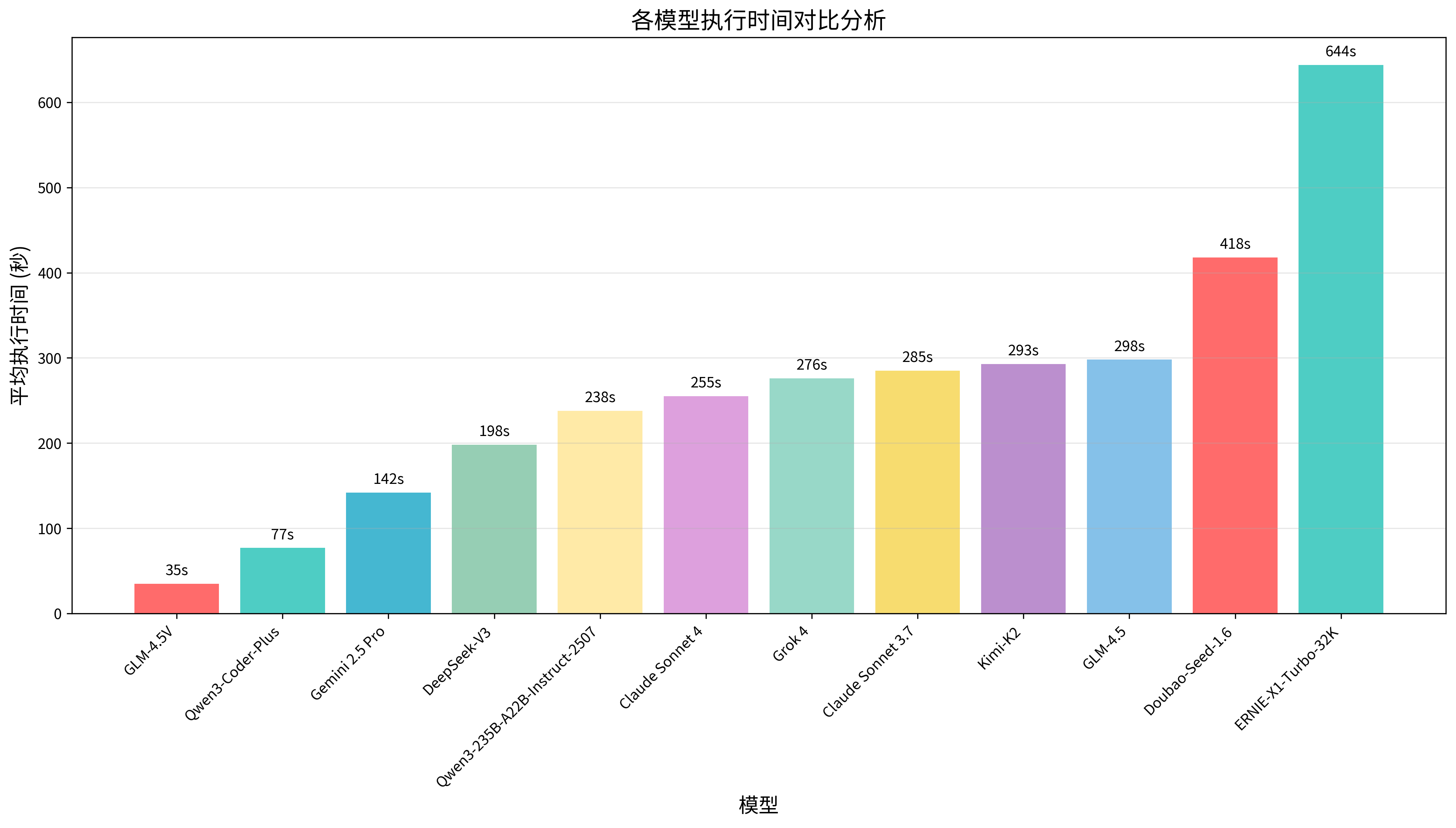
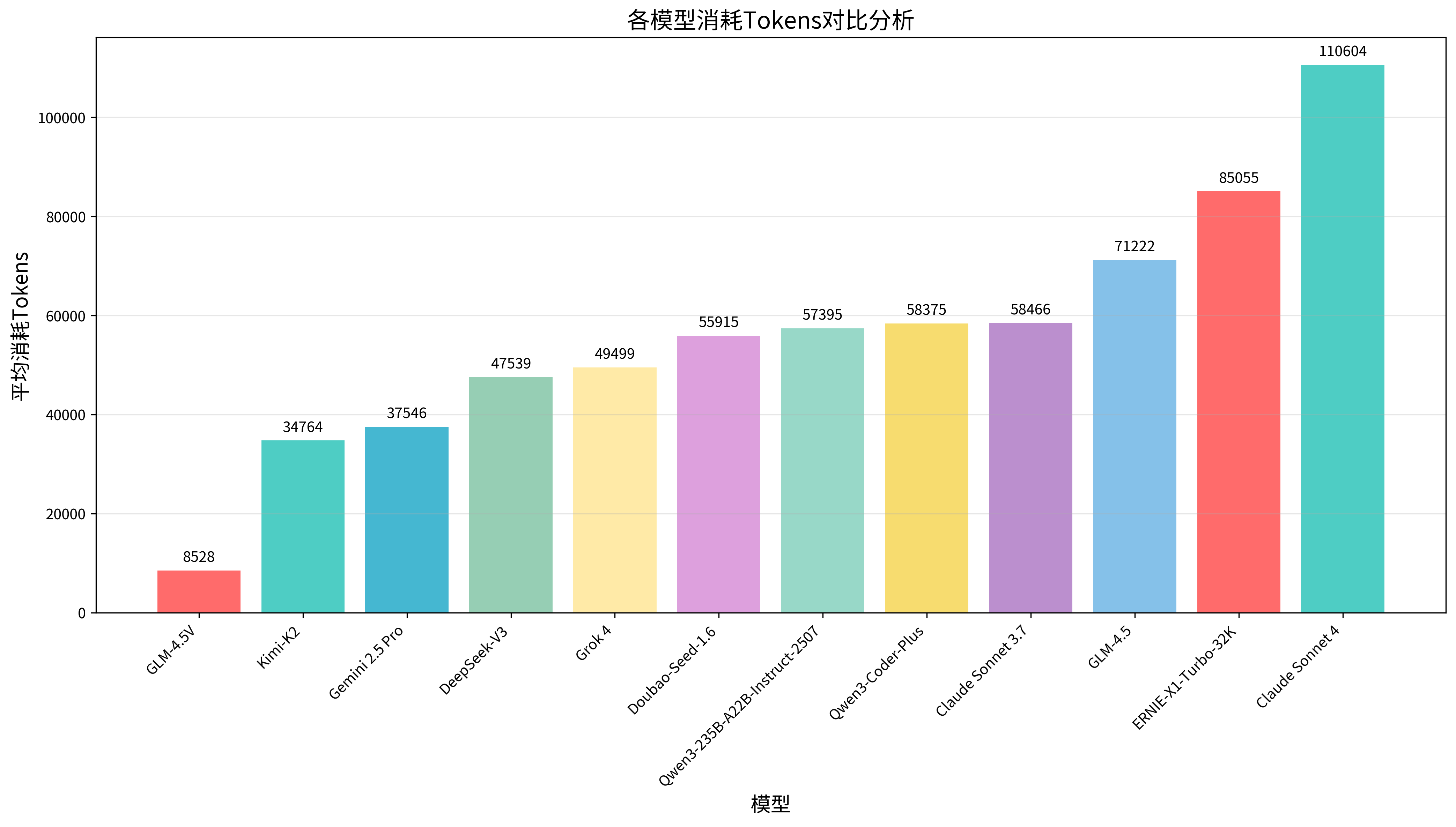
| 🥇1 | Claude Sonnet 4 | 80% | 255s | 110604 | 75 | Anthropic | |
| 🥈2 | Kimi-K2 | 70% | 293s | 34764 | 70 | 月之暗面 | |
| 🥉3 | Claude Sonnet 3.7 | 70% | 285s | 58466 | 69 | Anthropic | |
| 4 | GLM-4.5 | 70% | 298s | 71222 | 68 | 智谱华章 | |
| 5 | Gemini 2.5 Pro | 60% | 142s | 37546 | 62 | ||
| 6 | Qwen3-Coder-Plus | 60% | 77s | 58375 | 61 | 阿里 | |
| 7 | Qwen3-235B-A22B-Instruct-2507 | 60% | 238s | 57395 | 60 | 阿里 | |
| 8 | Doubao-Seed-1.6 | 60% | 418s | 55915 | 59 | 字节跳动 | |
| 9 | Grok 4 | 50% | 276s | 49499 | 51 | xAI | |
| 10 | DeepSeek-V3 | 40% | 198s | 47539 | 43 | 深度求索 | |
| 11 | ERNIE-X1-Turbo-32K | 40% | 644s | 85055 | 37 | 百度 | |
| 12 | GLM-4.5V | 10% | 35s | 8528 | 19 | 智谱华章 |
🇨🇳 国内模型排名情况
国内大模型在本次测评中依然展现出了强劲的竞争实力和快速的技术进步。从技术实现角度看,国内模型在中文理解、本土化应用场景适配方面具有天然优势,特别是在处理中文文档、理解中国用户需求等方面表现突出。Kimi-K2 的MoE架构在本次测评中效果明显,成为国内榜首,智谱华章的GLM-4.5、阿里的 Qwen3 系列、字节跳动的 Doubao-Seed-1.6表现稳健,但百度的 ERNIE-X1-Turbo-32K和智谱华章的 GLM-4.5V相对滞后。
| 国内排名 | 模型名称 | 成功率 | 综合得分 | 模型厂商 |
|---|---|---|---|---|
| 🥇1 | Kimi-K2 | 70% | 70 | 月之暗面 |
| 🥈2 | GLM-4.5 | 70% | 68 | 智谱华章 |
| 🥉3 | Qwen3-Coder-Plus | 60% | 61 | 阿里 |
| 4 | Qwen3-235B-A22B-Instruct-2507 | 60% | 60 | 阿里 |
| 5 | Doubao-Seed-1.6 | 60% | 59 | 字节跳动 |
| 6 | DeepSeek-V3 | 40% | 43 | 深度求索 |
| 7 | ERNIE-X1-Turbo-32K | 40% | 37 | 百度 |
| 8 | GLM-4.5V | 10% | 19 | 智谱华章 |
🇺🇸 国外模型排名情况
国外大模型中Claude凭借其在基础研究和算法创新方面的深厚积累,在本次测评中继续保持了技术领先优势,尤其在处理复杂多步骤任务时展现出了更强的逻辑连贯性和错误恢复能力,体现了其在核心算法和模型架构方面的技术优势。
| 国外排名 | 模型名称 | 成功率 | 综合得分 | 模型厂商 |
|---|---|---|---|---|
| 🥇1 | Claude Sonnet 4 | 80% | 75 | Anthropic |
| 🥈2 | Claude Sonnet 3.7 | 70% | 69 | Anthropic |
| 🥉3 | Gemini 2.5 Pro | 60% | 62 | |
| 4 | Grok 4 | 50% | 51 | xAI |
📊 各模型成功率对比分析
成功率是衡量模型实用性的核心指标,直接反映了模型在实际任务中的可靠性和稳定性。本次由于测评用例难度增强,没有达到100%成功率的模型,表现最佳的是Claude Sonnet 4,取得80%的成功率,反映出在高难度任务下,大模型仍有较大提升空间。
⚡ 各模型执行时间对比分析
执行时间反映了模型的响应效率和处理速度,是用户体验的重要组成部分。推理优化程度、以及服务器性能等因素相关。本次测评中时间差异显著,GLM-4.5V、Qwen3-Coder-Plus响应极快,而 ERNIE-X1-Turbo-32K 耗时最长,体现了模型架构设计与推理优化的差距。
💰 各模型消耗Tokens对比分析
Tokens消耗量直接关系到使用成本,是企业和个人用户选择模型时的重要考量因素。低Tokens消耗不仅意味着更低的使用成本,也反映了模型在信息处理和表达效率方面的优化程度。本次测评中,各模型在Tokens消耗方面表现出了显著差异,这与模型的训练方式、生成策略、以及对任务的理解深度密切相关。优秀的模型能够用更少的Tokens完成同样的任务,体现了更高的智能化水平和成本控制能力,但建议用户选择模型时结合成功率情况综合考量。
📈 各测试任务类型分布情况
本次测评涵盖了十大核心能力维度,全面考察了模型在不同应用场景下的表现。通过构建模型-任务类型成功率矩阵,我们能够深入分析各模型在特定领域的优势和短板。
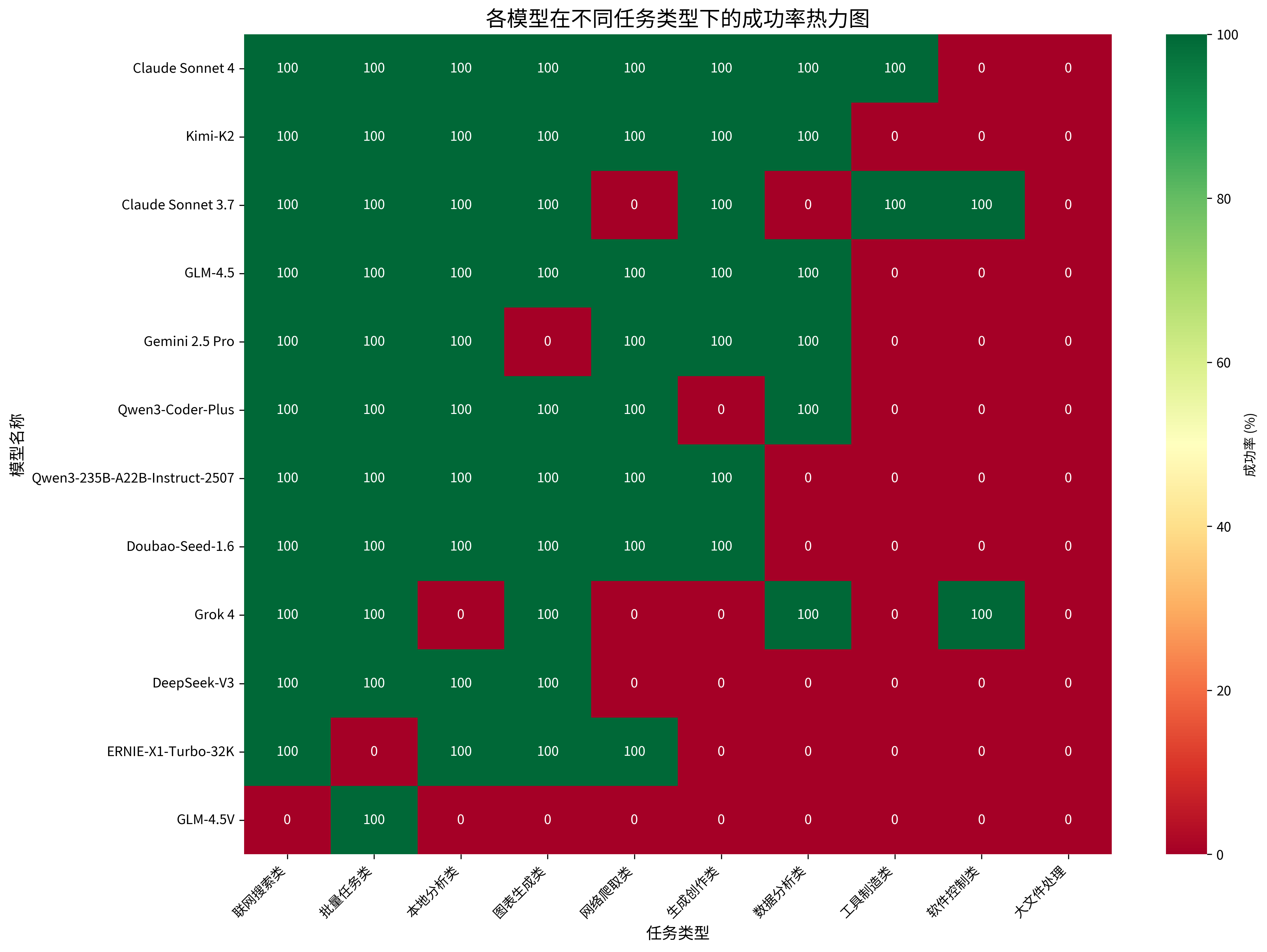
任务类型短板分析
- 大文件处理:本次测评中10G大文件处理无一成功,体现大模型在处理大文件时的任务规划和最大上下文限制问题。同时AiPy也会结合失败原因总结经验,从提示词优化和最佳实践角度弥补模型处理的短板。
- 软件控制类:软件控制类任务是本地Agent较常见的使用场景,本次任务让模型规划及编写代码控制邮箱发送邮件,经测试仅Claude Sonnet 3.7和Grok 4成功,用户在进行本地软件控制模型选择时可参考。
- 工具制造类:工具制造类任务考察模型任务规划、编程能力,本次测评中仅Claude系列成功,体现了Claude在编程和复杂任务处理中的优势。
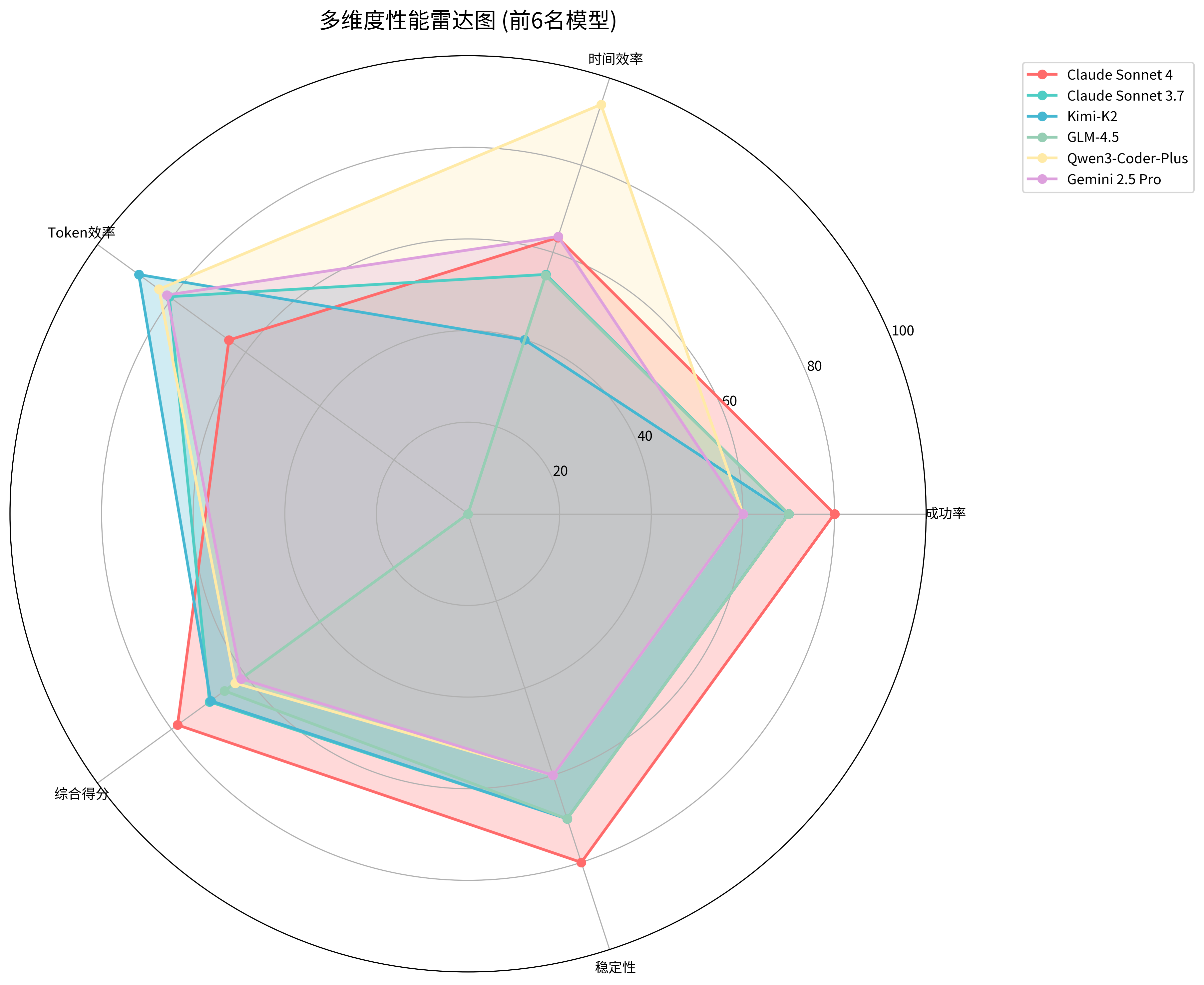
🎯 多维度性能雷达图
雷达图直观展示了顶级模型在五个关键维度上的综合表现:成功率体现任务完成的可靠性,时间效率反映响应速度,Tokens效率体现成本控制能力,综合得分代表整体水平,稳定性反映一致性表现。通过雷达图分析,我们可以清晰地看到每个模型的优势特征和相对短板,帮助用户根据自身需求选择最适合的模型。
🔍 失败原因分析
通过对测评过程中出现的失败案例进行深入分析,我们发现主要失败原因呈现出明显的分布特征。饼图清晰展示了各类失败原因的占比情况,为模型优化提供了精准的改进方向。在复杂任务处理中代码质量问题是失败的主要原因,其次是任务理解问题和代码未按照要求标记代码块。
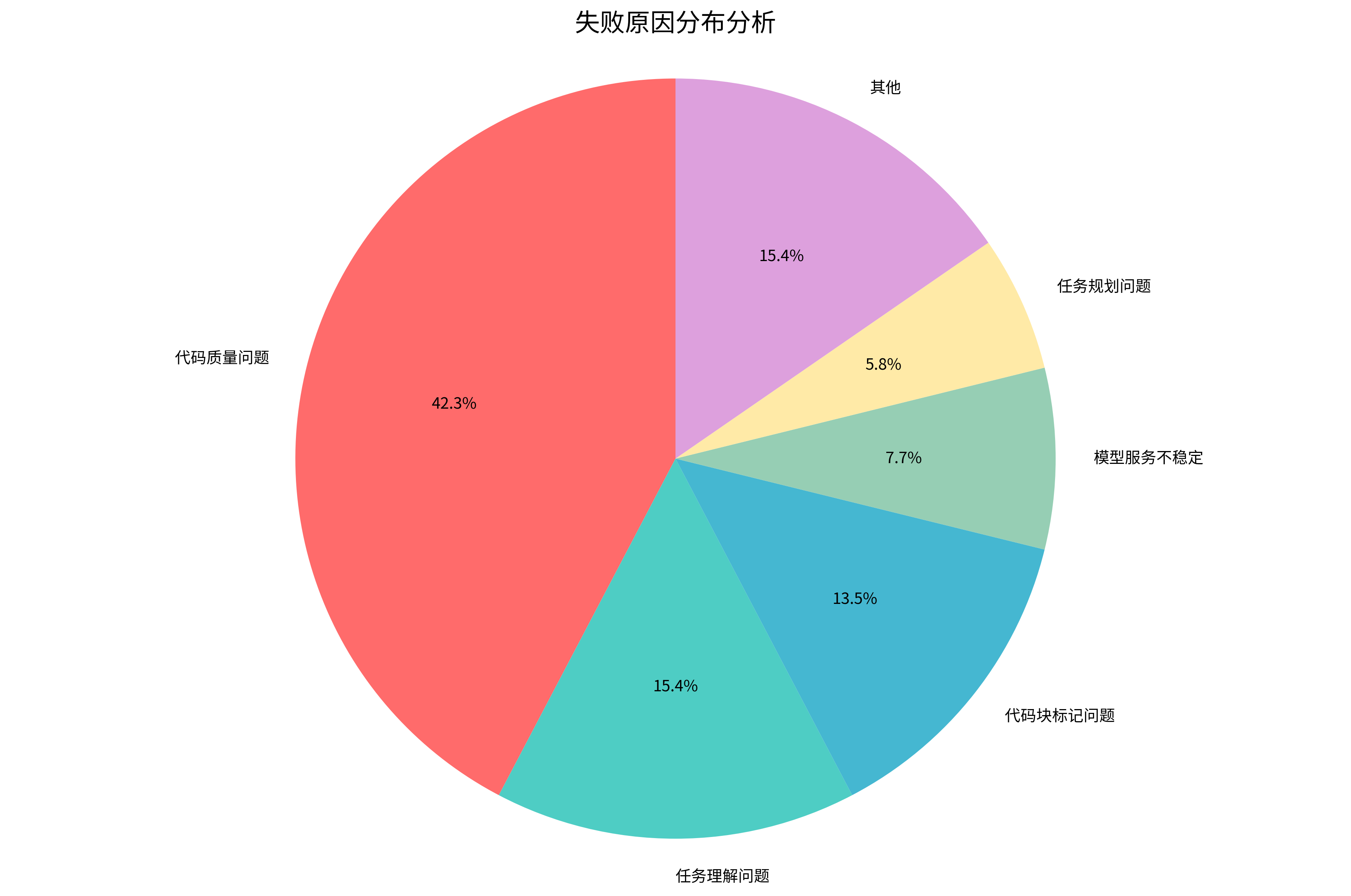
主要失败原因
- 代码质量问题:约占失败案例的43.3%,体现大模型在处理复杂任务时代码质量仍需持续加强
- 任务理解问题:约占失败案例的15.4%,大模型在多轮对话,复杂任务中的任务理解能力也需进一步改善
- 代码块标记问题:约占失败案例的13.5%,代码块标记是大模型和AiPy协作,实现动手动脚的关键步骤,模型代码块标记问题将直接导致AiPy失去行动能力,本次测评中GLM-4.5V模型标记问题较明显
📝 测试任务分类表
以下展示了本次测评中使用的核心测试任务,这些任务经过精心设计,涵盖了实际工作中的典型应用场景。每个任务都具有明确的目标和评判标准,确保测评结果的客观性和可比性。任务的选择充分考虑了不同行业和使用场景的需求,从简单的数据处理到复杂的系统集成,全面考察了模型的实用能力。通过这些真实场景的测试,我们能够更准确地评估模型在实际工作中的表现,为用户提供更有价值的参考信息。
| 序号 | 提示词 | 任务类型 |
|---|---|---|
| 1 | 查询我所在地区最近7天的天气,绘制一张天气趋势折线图。 | 图表生成类 |
| 2 | 请给6年级学生出具一份满分100分的数学试卷,要求保存为word格式,附带答案和解析。 | 生成创作类 |
| 3 | XX文件是网站访问日志,请先对日志字段进行分析,识别URL、IP、UA等关键信息,生成一份精美的HTML网站日志分析报告。 | 大文件处理 |
| 4 | 使用系统默认邮件客户端,给XXX发一封邮件,邮件主题为“test”邮件内容是:“test”,最后一步发送时控制键盘使用快捷键ctrl+enter发送。 | 软件控制类 |
| 5 | XXX是云防御黑白名单配置的API示例脚本,请帮我包装其中的功能为一个云防御配置工具.exe的程序保存到桌面。 | 工具制造类 |
| 6 | 请帮我批量将文件夹下所有文件中涉及的"sk-"密钥信息脱敏,并将脱敏的具体详情输出给我核对。 | 批量任务类 |
| 7 | 联网搜索“中芯国际”相关信息,做一份精美的公司调研分析报告。 | 联网搜索类 |
| 8 | 读取我的电脑浏览器的收藏夹,检查一下哪个链接失效了或者打不开,将建议清理的链接和原因输出为一份《浏览器收藏夹清理清单.xlsx》。 | 本地分析类 |
| 9 | 分析SQLite数据库中公司设备库存情况。 | 数据分析类 |
| 10 | 访问https://www.AiPyAiPy.com/首页,爬取AiPy和manus的区别相关内容并总结。 | 网络爬取类 |
💡 深度洞察
🏆 性能冠军
- Claude Sonnet 4以75.2分的综合得分夺得本次测评冠军,成功率达到80%,在各项指标上都表现出色。该模型在复杂任务处理、响应效率和成本控制方面都达到了行业领先水平,特别是在多步骤任务执行中保持了高度的一致性和可靠性,体现了其在核心算法和工程优化方面的技术优势。
- GLM-4.5和Kimi-K2在成功率方面仅次Claude Sonnet 4,在联网搜索、批量任务处理、本地文件分析、生成创作、图表生成等方面均表现优异,为用户本土化模型场景提供选择。
✨ 亮点发现
- Kimi-K2 作为国内模型的佼佼者,以 70% 成功率和 34764 tokens 的低消耗实现 "性能与成本" 双赢,在中文文档处理、本土化工具制造场景中,凭借对用户需求的精准捕捉,展现出 "接地气" 的技术优势,成为国产模型突围的典型代表。
- Qwen3-Coder-Plus 则以 77 秒的极速响应惊艳全场,在代码生成、批处理文件执行等任务中,将 "快准狠" 发挥到极致,虽综合排名第六,却在效率赛道上树立了新标杆,印证了专业化优化的技术价值。
📋 测评总结
本次测评展现了大模型技术在实战场景的进阶突破:12 款主流模型在十大核心能力维度的比拼中,整体成功率56%,印证了技术从实验室向产业化的跨越。
国外模型以 Claude 系列为代表,凭借复杂推理与多步骤任务连贯性的优势领跑,Claude Sonnet 4 以 80% 成功率和 75 分综合得分稳居榜首;国内模型则在中文理解与本土化适配中凸显特色,Kimi-K2 以 70% 成功率成为国产标杆,GLM-4.5紧随其后,Qwen3系列和豆包也表现良好。从性能看,模型分化明显:既有 Claude 系列的全能表现,也有 Qwen3-Coder-Plus的效率优势。但代码质量、任务理解偏差仍是共性短板,本次测评任务中未出现满分选手,提示大模型技术需在实战性复杂任务上持续突破。