AiPy通用能力测评为粉丝通用任务模型选型提供了重要参考,为进一步帮助专业用户选择专项任务的模型,AiPy模型测评团队在通用能力测评基础上启动了专项能力测评工作,专项能力将聚焦一类任务或能力进行针对性测评,如操作本地电脑、数据分析、UI识别与创作、编程开发、长指令遵循任务等,本期测评基于「本地电脑操作画图能力」,开展面向通用人工智能模型工具操控能力的横向对标测试。
测评依托 AiPy Agent 智能评测框架,采用统一提示工程驱动各参与模型,不使用多模态能力让模型在自主决策状态下完成端到端的工具链调用与视觉构建流程。该任务虽形式简洁,却深度考察了模型的通识理解能力(目标对象的几何表征、结构约束、细节语义)、序贯决策与规划执行能力(工具定位、操作编排、实时反馈调节)的双重核心竞争力。
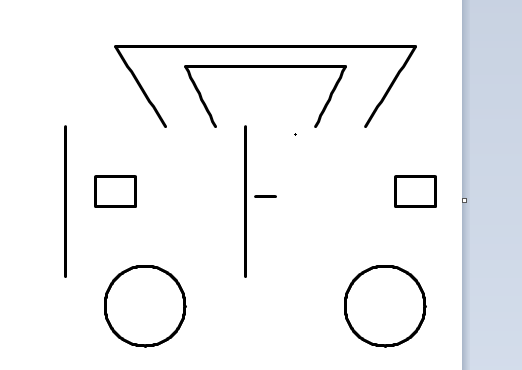
评估维度:基于任务完成度进行二分类判定——成功完整构建可识别的目标视觉表征即为通过;仅完成环境启动而未进行有效创作或输出不可辨识的形态,均判定为失败。
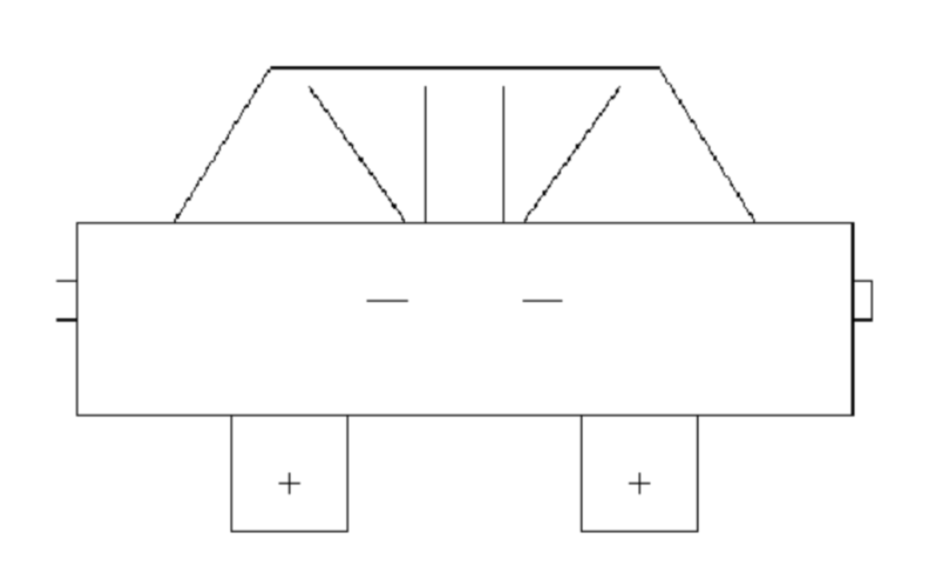
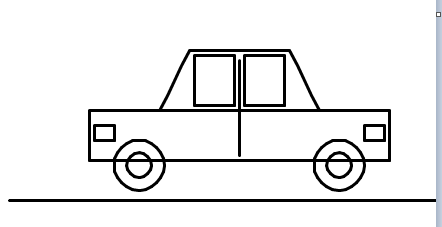
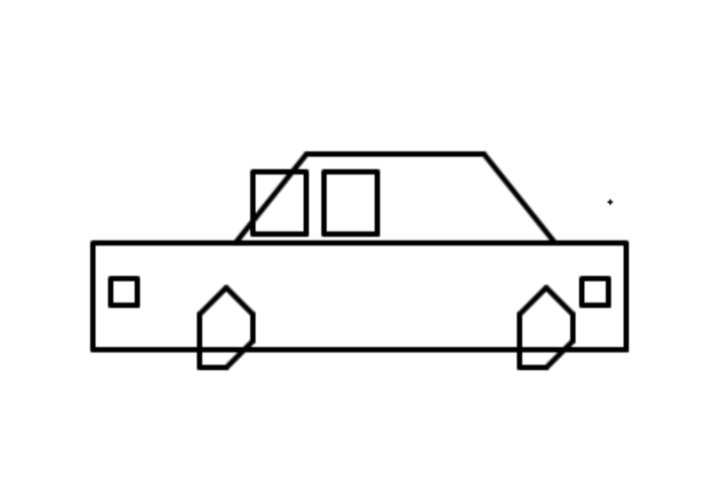
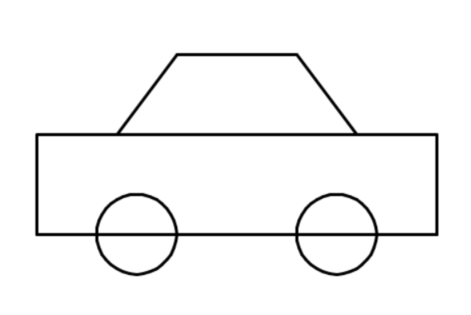

| # | 模型 | 结果 | 耗时 | Tokens消耗 | 厂商 | 国家 |
|---|---|---|---|---|---|---|
| 1 | Doubao-Seed-2.0-Pro-260215 | 成功 | 53s | 31,188 | 字节跳动 |
|
| 2 | GLM-5.1 | 成功 | 62s | 9,168 | 智谱华章 |
|
| 3 | GLM-5 | 成功 | 79s | 41,769 | 智谱华章 |
|
| 4 | Gemini-3.1-Pro-Preview | 成功 | 100s | 29,258 |
|
|
| 5 | Qwen3.6-Plus | 成功 | 169s | 24,048 | 阿里 |
|
| 6 | Claude-Sonnet-4.6 | 成功 | 232s | 271,707 | Anthropic |
|
| 7 | Hy3-preview | 成功 | 639s | 132,973 | 腾讯 |
|
| 8 | MiniMax-M2.5 | 失败 | 65s | 40,116 | 稀宇极智 |
|
| 9 | DeepSeek-v4-Flash | 失败 | 66s | 54,306 | 深度求索 |
|
| 10 | Hunyuan-2.0-Thinking-20251109 | 失败 | 92s | 16,229 | 腾讯 |
|
| 11 | Kimi-k2.5 | 失败 | 114s | 25,428 | 月之暗面 |
|
| 12 | GPT-5.2 | 失败 | 137s | 53,155 | OpenAI |
|
| 13 | DeepSeek-v4-Pro | 失败 | 160s | 37,367 | 深度求索 |
|
| 14 | Mimo-v2-omni | 失败 | 206s | 55,916 | 小米 |
|
| 15 | DeepSeek-V3.2 | 失败 | 879s | 123,528 | 深度求索 |
|
🌍 世界通识理解差距
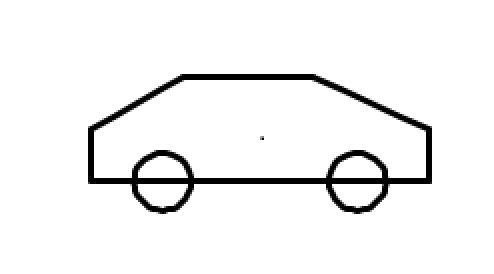
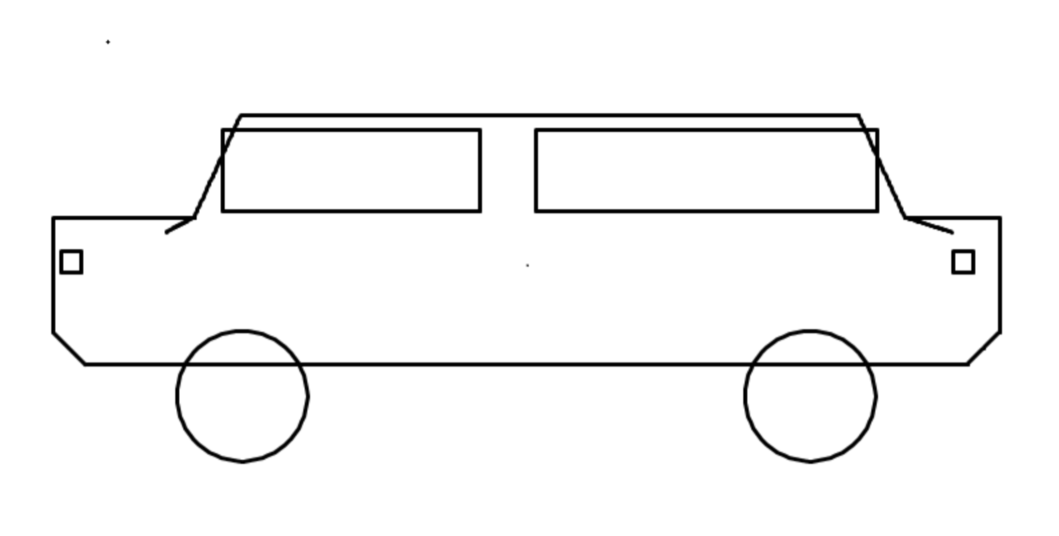
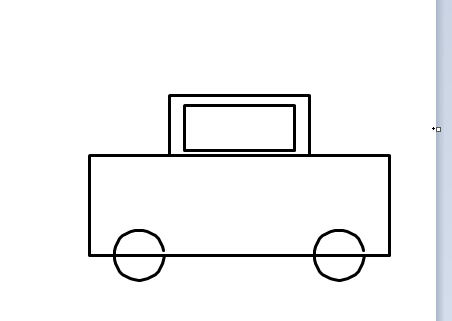
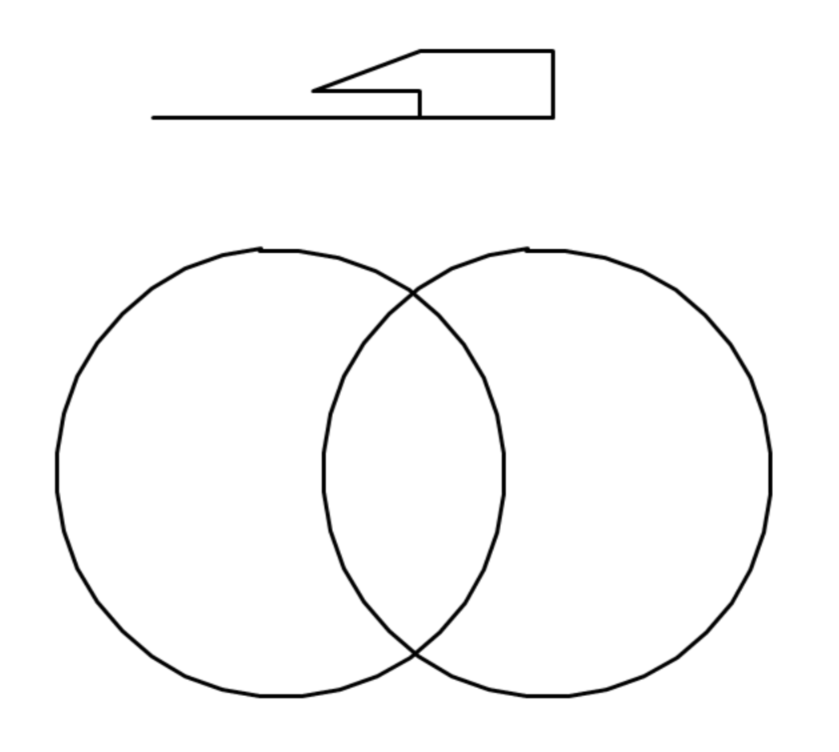
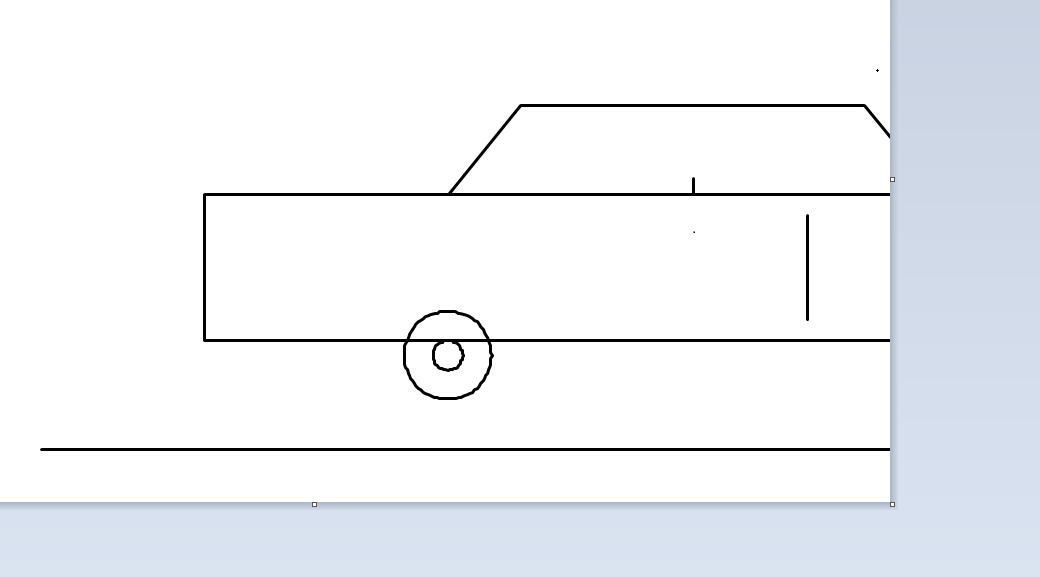
这道题的本质是考验模型对"汽车长什么样"的通识理解:车身轮廓、车轮比例、对称结构、车窗位置……这些是人类从小习得的常识。
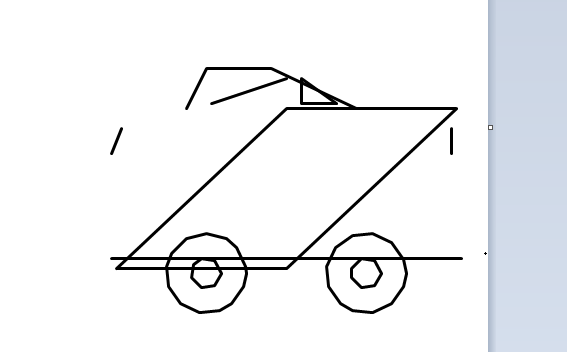
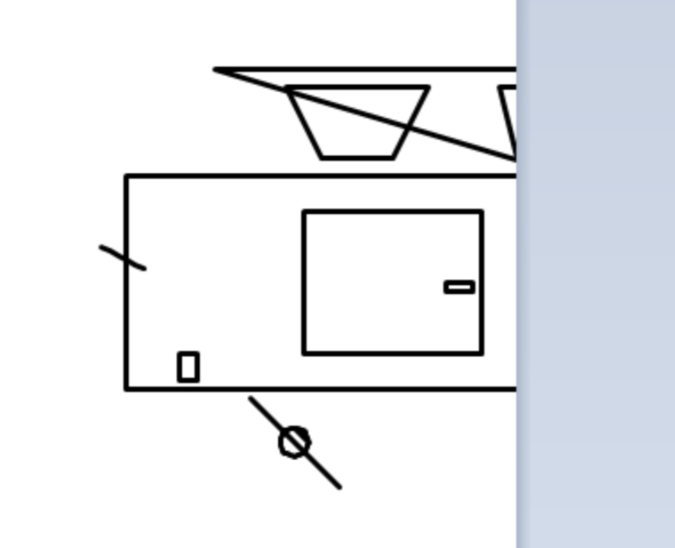
美国顶级模型(Gemini、Claude)在海量多模态数据训练下,形成了对真实世界的立体认知,虽GPT-5.2因没有定位对画布没画成功,但也能看出来小车基本形状其实是正确的;而部分国内模型因训练数据侧重文本/代码场景,对空间几何的理解存在明显短板,出现部分画图错乱及轮子竟然都不是圆形的情况。
最新发布模型中Hy3-preview成功完成任务,相比上版本提升明显,但DeepSeek v4系列(Pro和Flash)虽在执行效率上有显著提升(相比v3.2的879s,Pro仅需160s,Flash仅66s),画图效果仍不理想,反映出模型优化方向与通识理解能力之间的平衡仍需调整。
⚡ 效率与成本对比
从数据看,成功完成任务的模型中:
- Doubao-Seed-2.0-Pro-260215:仅53s,31K tokens,性价比最高,但不够精致 ⚡
- GLM-5.1:62s,9K tokens,耗时最短、token最省,国内效果最佳,升级后GLM5的轮子不圆,车窗位置不对的问题都改良了 🏆
- Gemini-3.1-Pro-Preview:100s,29K tokens,稳定高效
- Qwen3.6-Plus:169s,24K tokens,国内第三成功
- Claude-Sonnet-4.6:232s,271K tokens,最"话痨"但效果好
- Hy3-preview:639s,132K tokens,虽然耗时最长,但成功完成画图任务
💰 训练成本的本质
世界通识需要大量训练数据,而数据采购、清洗、标注需要巨额资金;训练本身需要算力卡和电力,同样需要钱。
- 部分国内模型采用专用数据训练
- 通过蒸馏获得单领域能力
- 适合编程、写作等窄场景,但丢失世界通识
- 这是性价比选择,不是技术落后,但长期仍需加强
通过这个简单但直观的测试,我们可以清晰地看到:美国顶级模型(Gemini、Claude)在世界通识理解上具有明显优势,能够将对汽车外形的抽象认知转化为具体的鼠标操作序列。
国内模型中,Doubao-Seed-2.0-Pro-260215、GLM-5.1、GLM-5、Qwen3.6-Plus 和 Hy3-preview 表现亮眼,均成功完成任务;其中 Doubao-Seed-2.0-Pro-260215 以最短耗时(53s)展现了执行效率,GLM-5.1 以仅 9K tokens 的超低消耗夺得性价比第一,同时画图效果也是是本次测评中国内模型的最佳表现,Hy3-preview 也成功完成了画图任务。
部分国内模型(DeepSeek-V3.2、DeepSeek-v4-Pro、DeepSeek-v4-Flash、Kimi-k2.5、MiniMax-M2.5、Hunyuan-2.0-Thinking、Mimo-v2-omni)在此类需要空间理解和通识推理的任务上表现不佳,反映出训练数据侧重和优化方向的差异——这不是简单的技术差距,而是训练策略选择的结果,期待后续的持续优化。值得注意的是,DeepSeek发布的v4系列Pro和Flash版本在此任务中均未成功,相比v3.2版本耗时大幅缩短(160s和66s vs 879s),但画图效果仍有提升空间。
我们在测评中深刻体会到:「部分国内的大模型缺乏对世界通识的理解。」这是一个值得行业深思的问题。